

















This topic describes the vector functions supported by OceanBase Database and their usage notes.
Considerations
- If the dimensions of the vectors are different, an error
different vector dimensions %d and %dis returned. - If the result exceeds the floating-point value range, an error
value out of range: overflow / underflowis returned. - The dense vector index supports L2, inner product (Inner Product), and cosine distance as index distance algorithms. The sparse vector index supports inner product and negative inner product (Negative Inner Product) as index distance algorithms. For more information, see Dense vector index. The sparse vector index distance algorithm is supported starting from V4.3.5 BP2.
- The vector index search supports the following distance functions:
L2_distance,Cosine_distance,Inner_product, andNegative_inner_product. It also supports the following similarity functions:inner_product_similarity,cosine_similarity, andl2_similarity.
Distance function
The distance function is used to calculate the distance between two vectors, and the specific calculation method varies depending on the distance algorithm.
L2_distance
The Euclidean distance reflects the distance between the coordinates of the compared vectors, which is essentially the straight-line distance between two vectors. It is calculated by applying the Pythagorean theorem to the vector coordinates:
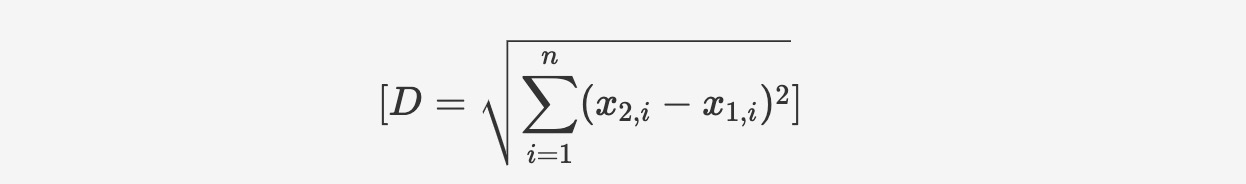
The function syntax is as follows:
l2_distance(vector v1, vector v2)
The parameters are described as follows:
In addition to the vector type, other types that can be strongly converted to the vector type, such as string types (e.g.,
'[1,2,3]'), are also accepted.The dimensions of the two parameters must be the same.
When a parameter of the single-level array type is present, the elements of the parameter must not contain
NULL.
The return value is described as follows:
The return value is a
distance(double)value.If any parameter is
NULL,NULLis returned.
Here is an example:
CREATE TABLE t1(c1 vector(3));
INSERT INTO t1 VALUES('[1,2,3]');
SELECT l2_distance(c1, [1,2,3]), l2_distance([1,2,3],[1,1,1]), l2_distance('[1,1,1]','[1,2,3]') FROM t1;
The return result is as follows:
+--------------------------+------------------------------+----------------------------------+
| l2_distance(c1, [1,2,3]) | l2_distance([1,2,3],[1,1,1]) | l2_distance('[1,1,1]','[1,2,3]') |
+--------------------------+------------------------------+----------------------------------+
| 0 | 2.23606797749979 | 2.23606797749979 |
+--------------------------+------------------------------+----------------------------------+
1 row in set
L2_squared
The L2 Squared distance is the square of the Euclidean distance (L2 Distance). It omits the square root operation in the Euclidean distance formula, thereby reducing the computational cost while maintaining the relative order of distances. The calculation method is as follows:
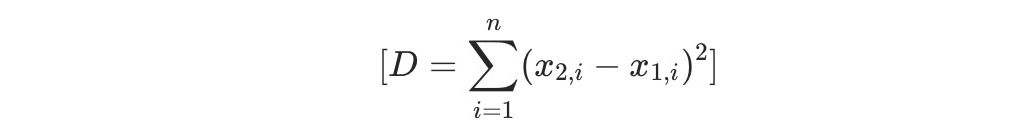
The syntax is as follows:
l2_squared(vector v1, vector v2)
The parameters are described as follows:
In addition to the vector type, other types that can be strongly converted to the vector type, such as string types (e.g.,
'[1,2,3]'), are also accepted.The dimensions of the two parameters must be the same.
When a parameter of the single-level array type is present, the elements of the parameter must not contain
NULL.
The return value is described as follows:
The return value is a
distance(double)value.If any parameter is
NULL,NULLis returned.
Here is an example:
CREATE TABLE t1(c1 vector(3));
INSERT INTO t1 VALUES('[1,2,3]');
SELECT l2_squared(c1, [1,2,3]), l2_squared([1,2,3],[1,1,1]), l2_squared('[1,1,1]','[1,2,3]') FROM t1;
The return result is as follows:
+-------------------------+-----------------------------+---------------------------------+
| l2_squared(c1, [1,2,3]) | l2_squared([1,2,3],[1,1,1]) | l2_squared('[1,1,1]','[1,2,3]') |
+-------------------------+-----------------------------+---------------------------------+
| 0 | 5 | 5 |
+-------------------------+-----------------------------+---------------------------------+
1 row in set
L1_distance
The Manhattan distance is used to calculate the sum of the absolute axis distances between two points in a standard coordinate system. The calculation formula is as follows:
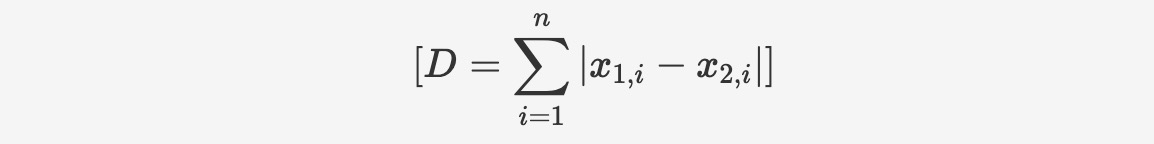
The function syntax is as follows:
l1_distance(vector v1, vector v2)
The parameters are described as follows:
In addition to the vector type, other types that can be strongly converted to the vector type, such as string types (e.g.,
'[1,2,3]'), are also accepted.The dimensions of the two parameters must be the same.
When a parameter of the single-level array type is present, the elements of the parameter must not contain
NULL.
The return value is described as follows:
The return value is a
distance(double)value.If any parameter is
NULL,NULLis returned.
Here is an example:
CREATE TABLE t2(c1 vector(3));
INSERT INTO t2 VALUES('[1,2,3]');
INSERT INTO t2 VALUES('[1,1,1]');
SELECT l1_distance(c1, [1,2,3]) FROM t2;
The return result is as follows:
+--------------------------+
| l1_distance(c1, [1,2,3]) |
+--------------------------+
| 0 |
| 3 |
+--------------------------+
2 rows in set
Cosine_distance
Cosine similarity measures the angular difference between two vectors, reflecting their similarity in direction regardless of their magnitude. The cosine similarity ranges from [-1, 1], where 1 indicates the vectors are in the same direction, 0 indicates they are orthogonal, and -1 indicates they are in opposite directions.
The calculation method for cosine similarity is as follows:
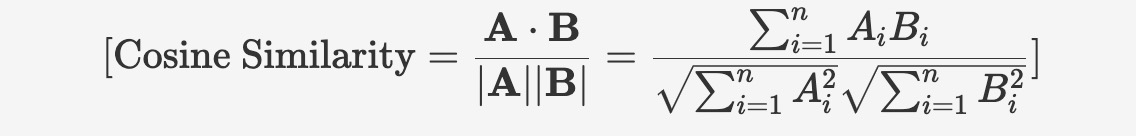
Since cosine similarity closer to 1 indicates greater similarity, cosine distance (or cosine dissimilarity) is sometimes used as a measure of distance between vectors. Cosine distance can be calculated by subtracting cosine similarity from 1:
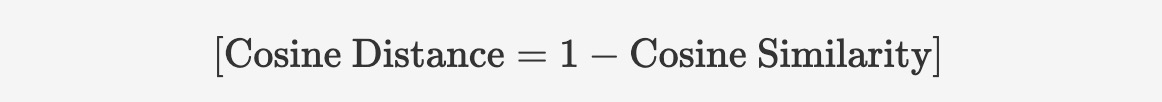
The cosine distance ranges from [0, 2], where 0 indicates the vectors are in the same direction (no distance), and 2 indicates they are in opposite directions.
The function syntax is as follows:
cosine_distance(vector v1, vector v2)
The parameters are described as follows:
In addition to the vector type, other types that can be strongly converted to the vector type, such as string types (e.g.,
'[1,2,3]'), are also accepted.The dimensions of the two parameters must be the same.
When a parameter of the single-level array type is present, the elements of the parameter must not contain
NULL.
The return value is described as follows:
The return value is a
distance(double)value.If any parameter is
NULL,NULLis returned.
Here is an example:
CREATE TABLE t3(c1 vector(3));
INSERT INTO t3 VALUES('[1,2,3]');
INSERT INTO t3 VALUES('[1,2,1]');
SELECT cosine_distance(c1, [1,2,3]) FROM t3;
+------------------------------+
| cosine_distance(c1, [1,2,3]) |
+------------------------------+
| 0 |
| 0.12712843905603044 |
+------------------------------+
2 rows in set
Inner_product
The inner product, also known as the dot product or scalar product, represents a type of multiplication between two vectors. In a geometric sense, the inner product indicates the directional and magnitude relationship between two vectors. The inner product is calculated as follows:
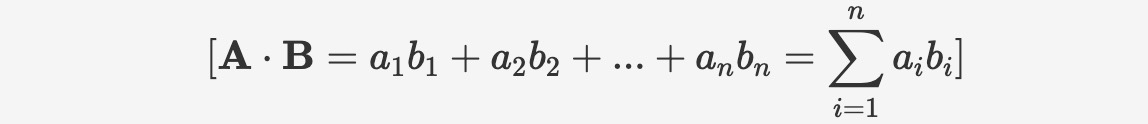
The syntax is as follows:
inner_product(vector v1, vector v2)
The parameters are described as follows:
In addition to vector types, the parameters can accept any other types that can be explicitly converted to vector types, such as string types (e.g.,
'[1,2,3]').The dimensions of the two parameters must be the same.
If a parameter is of the single-level array type, the elements of the parameter cannot be
NULL.When using this function with sparse vectors, one of the parameters can be a sparse vector string, such as
c2,'{1:2.4}'. However, both parameters cannot be strings.
The return value is described as follows:
The return value is a
distance(double)value.If any parameter is
NULL, the return value isNULL.
Here is an example of dense vectors:
CREATE TABLE t4(c1 vector(3));
INSERT INTO t4 VALUES('[1,2,3]');
INSERT INTO t4 VALUES('[1,2,1]');
SELECT inner_product(c1, [1,2,3]) FROM t4;
The return result is as follows:
+----------------------------+
| inner_product(c1, [1,2,3]) |
+----------------------------+
| 14 |
| 8 |
+----------------------------+
2 rows in set
Here is an example of sparse vectors:
CREATE TABLE t4(c1 INT, c2 SPARSEVECTOR, c3 SPARSEVECTOR);
INSERT INTO t4 VALUES(1, '{1:1.1, 2:2.2}', '{1:2.4}');
INSERT INTO t4 VALUES(2, '{1:1.5, 3:3.6}', '{4:4.5}'));
SELECT inner_product(c2,c3) FROM t4;
The return result is as follows:
```shell
+----------------------+
| inner_product(c2,c3) |
+----------------------+
| 2.640000104904175 |
| 0 |
+----------------------+
2 rows in set
Negative_inner_product
Negative_inner_product is used to calculate the negative inner product between two vectors. The calculation method is as follows:
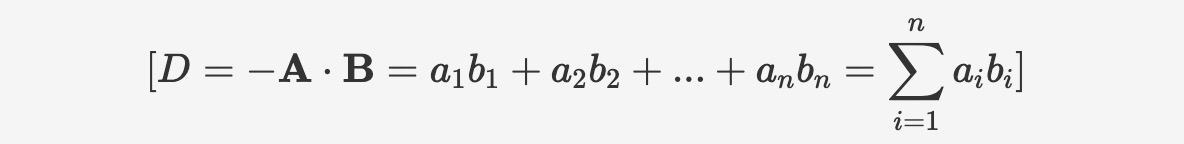
The syntax is as follows:
negative_inner_product(vector v1, vector v2)
The parameters are described as follows:
In addition to vector types, the parameters can accept any other types that can be explicitly converted to vector types, such as string types (e.g.,
'[1,2,3]').The dimensions of the two parameters must be the same.
If a parameter is of the single-level array type, the elements of the parameter cannot be
NULL.When using this function with sparse vectors, one of the parameters can be a sparse vector string, such as
c2,'{1:2.4}'. However, both parameters cannot be strings.
The return value is described as follows:
The return value is a
distance(double)value.If any parameter is
NULL, the return value isNULL.
Here is an example of dense vectors:
CREATE TABLE t5(c1 vector(3));
INSERT INTO t5 VALUES('[1,2,3]');
INSERT INTO t5 VALUES('[1,2,1]');
SELECT negative_inner_product(c1, [1,2,3]) FROM t5;
The return result is as follows:
+-------------------------------------+
| negative_inner_product(c1, [1,2,3]) |
+-------------------------------------+
| -14 |
| -8 |
| -14 |
| -8 |
+-------------------------------------+
4 rows in set
Here is an example of sparse vectors:
CREATE TABLE t5(c1 INT, c2 SPARSEVECTOR, c3 SPARSEVECTOR);
INSERT INTO t5 VALUES(1, '{1:1.1, 2:2.2}', '{1:2.4}');
INSERT INTO t5 VALUES(2, '{1:1.5, 3:3.6}', '{4:4.5}'));
SELECT negative_inner_product(c2,c3) FROM t5;
The return result is as follows:
+-------------------------------+
| negative_inner_product(c2,c3) |
+-------------------------------+
| -2.640000104904175 |
| 0 |
+-------------------------------+
2 rows in set
Vector_distance
vector_distance is used to calculate the distance between two vectors. You can specify parameters to select different distance algorithms.
The syntax is as follows:
vector_distance(vector v1, vector v2 [, string metric])
The vector v1/v2 parameters are described as follows:
In addition to vector types, the parameters can accept any other types that can be explicitly converted to vector types, such as string types (e.g.,
'[1,2,3]').The dimensions of the two parameters must be the same.
If a parameter is of the single-level array type, the elements of the parameter cannot be
NULL.
The metric parameter specifies the distance algorithm. The value can be:
If not specified, the default algorithm is
euclidean.If specified, the value can only be:
euclidean: specifies the Euclidean distance, which is the same as L2_distance.manhattan: specifies the Manhattan distance, which is the same as L1_distance.cosine: specifies the cosine distance, which is the same as Cosine_distance.dot: specifies the inner product, which is the same as Inner_product.
The return value is described as follows:
The return value is a
distance(double)value.If any parameter is
NULL, the return value isNULL.
Here is an example:
CREATE TABLE t5(c1 vector(3));
INSERT INTO t5 VALUES('[1,2,3]');
INSERT INTO t5 VALUES('[1,2,1]');
SELECT vector_distance(c1, [1,2,3], euclidean) FROM t5;
The return result is as follows:
+-----------------------------------------+
| vector_distance(c1, [1,2,3], euclidean) |
+-----------------------------------------+
| 0 |
| 2 |
+-----------------------------------------+
2 rows in set
Similarity functions
A similarity function measures the similarity between two vectors. A higher value indicates a greater similarity. It is the inverse concept of a distance function: higher similarity means a smaller distance. In vector search, you can set a similarity threshold to filter out results that do not meet the criteria.
inner_product_similarity
inner_product_similarity calculates the inner product similarity between two vectors. The return value is calculated in the same way as the inner product distance function inner_product, but it represents similarity instead of distance. The conversion between inner_product_similarity and inner_product is as follows: inner_product_similarity(v1, v2) = (1 + inner_product(v1, v2) / (vector_norm(v1) * vector_norm(v2))) / 2. The vector_norm function calculates the Euclidean norm (magnitude) of a vector, which represents the Euclidean distance between the vector and the origin. For a vector v = [v1, v2, v3, ..., vn], the norm is calculated as: vector_norm(v) = √(v1² + v2² + v3² + ... + vn²).
Syntax:
inner_product_similarity(vector v1, vector v2)
Parameters:
- In addition to the vector type, other types that can be strongly cast to the vector type, such as string types (e.g.,
'[1,2,3]'), are also supported. - The dimensions of the two parameters must be the same.
- If a single-level array type parameter is present, the elements of this parameter cannot contain
NULL.
Return value:
- The return value is of type double, representing the similarity between the two vectors. A higher value indicates greater similarity.
- If any parameter is
NULL, the return value isNULL.
Example:
CREATE TABLE t12(c1 vector(3));
INSERT INTO t12 VALUES('[1,2,3]');
INSERT INTO t12 VALUES('[1,2,1]');
SELECT inner_product_similarity(c1, [1,2,3]) FROM t12;
The return result is as follows:
+---------------------------------------+
| inner_product_similarity(c1, [1,2,3]) |
+---------------------------------------+
| 0.9999999552965164 |
| 0.9364357516169548 |
+---------------------------------------+
2 rows in set
Or more simply:
SELECT inner_product_similarity([1,0,0], [0,1,0]);
The return result is as follows:
+--------------------------------------------+
| inner_product_similarity([1,0,0], [0,1,0]) |
+--------------------------------------------+
| 0.5 |
+--------------------------------------------+
1 row in set
cosine_similarity
cosine_similarity calculates the cosine similarity between two vectors, reflecting their directional similarity, regardless of their lengths. The calculation is as follows: cosine_similarity(v1, v2) = 1 - (cosine_distance(v1, v2) / 2).
Syntax:
cosine_similarity(vector v1, vector v2)
Parameters:
- In addition to the vector type, other types that can be strongly cast to the vector type, such as string types (e.g.,
'[1,2,3]'), are also supported. - The dimensions of the two parameters must be the same.
- If a single-level array type parameter is present, the elements of this parameter cannot contain
NULL.
Return value:
- The return value is of type double, representing the similarity between the two vectors. The value ranges from
[-1, 1], where1indicates that the vectors are in the same direction,0indicates orthogonality, and-1indicates that the vectors are in opposite directions. A higher value indicates greater similarity. - If any parameter is
NULL, the return value isNULL.
Example:
CREATE TABLE t13(c1 vector(3));
INSERT INTO t13 VALUES('[1,2,3]');
INSERT INTO t13 VALUES('[1,2,1]');
SELECT cosine_similarity(c1, [1,2,3]) FROM t13;
The return result is as follows:
+--------------------------------+
| cosine_similarity(c1, [1,2,3]) |
+--------------------------------+
| 0.9999999552965164 |
| 0.9364357516169548 |
+--------------------------------+
2 rows in set
Or more simply:
SELECT cosine_similarity([1,0,0], [0,1,0]);
The return result is as follows:
+-------------------------------------+
| cosine_similarity([1,0,0], [0,1,0]) |
+-------------------------------------+
| 0.5 |
+-------------------------------------+
1 row in set
l2_similarity
l2_similarity calculates the L2 similarity between two vectors. L2 similarity is based on the Euclidean distance, but it represents similarity instead of distance. A higher similarity value indicates greater similarity between the two vectors. The conversion between l2_similarity and l2_squared is as follows: l2_similarity(v1, v2) = 1 / (1 + l2_squared(v1, v2)).
Syntax:
l2_similarity(vector v1, vector v2)
Parameters:
- In addition to the vector type, other types that can be strongly cast to the vector type, such as string types (e.g.,
'[1,2,3]'), are also supported. - The dimensions of the two parameters must be the same.
- If a single-level array type parameter is present, the elements of this parameter cannot contain
NULL.
Return value:
- The return value is of type double, representing the similarity between the two vectors. A higher value indicates greater similarity.
- If any parameter is
NULL, the return value isNULL.
Example:
CREATE TABLE t14(c1 vector(3));
INSERT INTO t14 VALUES('[1,2,3]');
INSERT INTO t14 VALUES('[1,2,1]');
SELECT l2_similarity(c1, [1,2,3]) FROM t14;
The return result is as follows:
+----------------------------+
| l2_similarity(c1, [1,2,3]) |
+----------------------------+
| 1 |
| 0.2 |
+----------------------------+
2 rows in set
Alternatively, you can run the following statement:
SELECT l2_similarity([1,0,0], [0,1,0]);
The return result is as follows:
+---------------------------------+
| l2_similarity([1,0,0], [0,1,0]) |
+---------------------------------+
| 0.3333333333333333 |
+---------------------------------+
1 row in set
Arithmetic functions
Arithmetic functions provide arithmetic operations, including addition, subtraction, and multiplication, between vector types, single-level array types, and special string types. The operations are performed element-wise. For example, the addition operation is performed as follows:
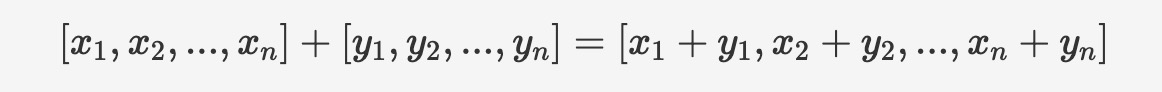
Syntax:
v1 + v2
v1 - v2
v1 * v2
Parameters:
In addition to vector types, the parameters can be any type that can be explicitly converted to a vector type, such as string types (e.g.,
'[1,2,3]'). Note: One of the two parameters must be a vector type.The dimensions of the two parameters must be the same.
When a single-level array type is specified as a parameter, the elements in the array cannot be
NULL.
Return value:
If at least one of the two parameters is a vector type, the return value is a vector type that is the same as the vector parameter.
If both parameters are single-level arrays, the return value is of the
array(float)type.If any parameter is
NULL, the return value isNULL.
Example:
CREATE TABLE t6(c1 vector(3));
INSERT INTO t6 VALUES('[1,2,3]');
SELECT [1,2,3] + '[1.12,1000.0001, -1.2222]', c1 - [1,2,3] FROM t6;
The return result is as follows:
+---------------------------------------+--------------+
| [1,2,3] + '[1.12,1000.0001, -1.2222]' | c1 - [1,2,3] |
+---------------------------------------+--------------+
| [2.12,1002,1.7778] | [0,0,0] |
+---------------------------------------+--------------+
1 row in set
Comparison functions
Comparison functions provide comparison operations between vector types, single-level array types, and special string types. The supported comparison operators are =, !=, >, <, >=, and <=. The comparisons are performed element-wise in lexicographical order.
Syntax:
v1 = v2
v1 != v2
v1 > v2
v1 < v2
v1 >= v2
v1 <= v2
Parameters:
- In addition to vector types, the parameters can be any type that can be explicitly converted to a vector type, such as string types (e.g.,
'[1,2,3]').
Notice
One of the two parameters must be a vector type.
The dimensions of the two parameters must be the same.
When a single-level array type is specified as a parameter, the elements in the array cannot be
NULL.
Return value:
The return value is of the bool type.
If any parameter is
NULL, the return value isNULL.
Example:
CREATE TABLE t7(c1 vector(3));
INSERT INTO t7 VALUES('[1,2,3]');
SELECT c1 = '[1,2,3]' FROM t7;
The return result is as follows:
+----------------+
| c1 = '[1,2,3]' |
+----------------+
| 1 |
+----------------+
1 row in set
Aggregate functions
Notice
You cannot use a vector column as a GROUP BY condition. The DISTINCT clause is not supported.
Sum
The sum function calculates the sum of the vector column in the table. The sum is calculated by element-wise accumulation to obtain the vector.
Syntax:
sum(vector v1)
Parameters:
- Only vector types are supported.
Return value:
- The return value is the
sum (vector)value.
Example:
CREATE TABLE t8(c1 vector(3));
INSERT INTO t8 VALUES('[1,2,3]');
SELECT sum(c1) FROM t8;
The return result is as follows:
+---------+
| sum(c1) |
+---------+
| [1,2,3] |
+---------+
1 row in set
Avg
The avg function calculates the average value of the vector column in the table.
Syntax:
avg(vector v1)
Parameters:
- Only vector types are supported.
Return value:
The return value is the
avg (vector)value.The
NULLrows in the vector column are not counted.If the input parameter is empty, the return value is
NULL.
Example:
CREATE TABLE t9(c1 vector(3));
INSERT INTO t9 VALUES('[1,2,3]');
SELECT avg(c1) FROM t9;
The return result is as follows:
+---------+
| avg(c1) |
+---------+
| [1,2,3] |
+---------+
1 row in set
Other common vector functions
Vector_norm
The vector_norm function calculates the Euclidean norm (magnitude) of the vector, which represents the Euclidean distance between the vector and the origin. The calculation is performed as follows:
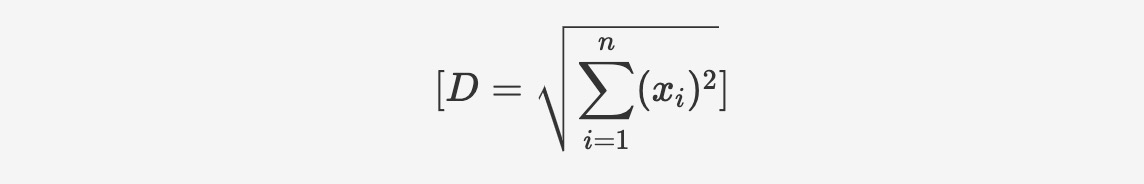
Syntax:
vector_norm(vector v1)
Parameters:
In addition to vector types, the parameters can be any type that can be explicitly converted to a vector type, such as string types (e.g.,
'[1,2,3]').When a single-level array type is specified as a parameter, the elements in the array cannot be
NULL.
Return value:
The return value is the
norm(double)value.If the parameter is
NULL, the return value isNULL.
Example:
CREATE TABLE t10(c1 vector(3));
INSERT INTO t10 VALUES('[1,2,3]');
SELECT vector_norm(c1),vector_norm([1,2,3]) FROM t10;
The return result is as follows:
+--------------------+----------------------+
| vector_norm(c1) | vector_norm([1,2,3]) |
+--------------------+----------------------+
| 3.7416573867739413 | 3.7416573867739413 |
+--------------------+----------------------+
1 row in set
Vector normalization
Vector normalization is the process of standardizing the length (magnitude) of a vector to 1. The vector_norm function is commonly used to achieve vector normalization.
For vector indexes using the l2_distance distance type, it is recommended to normalize the vectors to improve the accuracy of similarity searches. After normalization, the magnitude of the vector is 1, and the range of L2 distances is limited to [0, 2], preventing precision issues caused by excessively small similarity values.
For example, for the vector [3, 4]:
- The magnitude of the vector:
vector_norm([3, 4]) = √(3² + 4²) = 5 - After normalization:
[3, 4] / 5 = [0.6, 0.8]
The magnitude of the normalized vector is 1, which can be verified as follows:
SELECT vector_norm([0.6, 0.8]);
The return result is as follows:
+-------------------------+
| vector_norm([0.6, 0.8]) |
+-------------------------+
| 1.000000029802322 |
+-------------------------+
1 row in set
Vector_dims
The vector_dims function returns the dimension of a vector.
Syntax:
vector_dims(vector v1)
Parameters:
- In addition to vectors, parameters can be any type that can be strongly converted to a vector, such as strings (e.g.,
'[1,2,3]').
Return value:
Returns the dimension value as
dims(int64).If the parameter is
NULL, an error will be returned.
Here is an example:
CREATE TABLE t11(c1 vector(3));
INSERT INTO t11 VALUES('[1,2,3]');
INSERT INTO t11 VALUES('[1,1,1]');
SELECT vector_dims(c1), vector_dims('[1,2,3]') FROM t11;
The return result is as follows:
+-----------------+------------------------+
| vector_dims(c1) | vector_dims('[1,2,3]') |
+-----------------+------------------------+
| 3 | 3 |
| 3 | 3 |
+-----------------+------------------------+
2 rows in set
Semantic index-related functions
In addition to the general vector functions mentioned above, OceanBase Database provides vector search functions specifically for semantic indexes (vector indexes created on text columns):
semantic_distance(column_name, 'query_text'): Performs vector retrieval using the original text. The system automatically calls the embedding model to convert the text into a vector.semantic_vector_distance(column_name, query_vector): Performs vector retrieval using the vector. It supports both index-based retrieval (with theAPPROXIMATEorAPPROXclause) and full-table scan (without theAPPROXIMATEorAPPROXclause).
These two functions are specifically designed for semantic index scenarios. For more details and examples, see Semantic index.