
Meet OceanBase AI Database, the unified database for operational data, real-time analytics, and AI. Explore ->
Meet OceanBase AI Database, the unified database for operational data, real-time analytics, and AI. Explore ->
Inside OceanBase's High Availability Architecture: A Kernel-Level Walkthrough

- OceanBase's kernel implements three layered high availability mechanisms — multi-replica Paxos, arbitration-based recovery, and tenant-level physical standby — each tuned for a different failure domain.
- Multi-replica disaster recovery delivers RPO = 0 and RTO < 8s for minority failures, built on Paxos-backed Append-only Log File System (PALF) running over the log stream, OceanBase 4.x's atomic commit unit.
- The arbitration service breaks the classic "maximum protection vs. maximum availability" deadlock by adding a lightweight voter that enables automatic degrade — with no risk of split-brain.
Every database product page lists "high availability" as a feature. Open ten of them and you'll see the same phrase paired with very different mechanics underneath. One vendor's HA is asynchronous replication with a 5-minute RPO. Another's is a primary-replica cluster that requires a human to flip the switch during failover. A third claims zero data loss — but only inside a single rack.
The gap matters most at 3 AM. When a network partition splits a cluster in half, "high availability" collapses into three uncomfortable questions: How much data did we just lose? How long until we're back? And how confident are we that we don't have two leaders right now?
OceanBase answers those questions through three distinct kernel-level HA mechanisms — each designed for a different blast radius. This post is a walkthrough of how they work, where they fit, and what trade-offs each one makes explicit. We'll focus on service availability here; data reliability (backups, archive logs, point-in-time recovery) belongs in a separate discussion.
The Foundation: Log Streams and PALF
Before the mechanisms, the substrate. Two concepts do most of the heavy lifting.
Log streams are the atomic unit of transaction commitment in OceanBase 4.x. A log stream owns a collection of partitions plus the redo log (clog) and transaction-context manager for that group. In 3.x, transactions committed at the partition level — every partition ran its own two-phase commit. The 4.x shift to log-stream-level commits drastically reduces per-transaction overhead and gives the consensus layer a cleaner boundary to operate on.
PALF — the Paxos-backed Append-only Log File System, is what runs inside the log stream to replicate the clog across replicas. It implements Multi-Paxos, not Raft, and the distinction matters in two places:
- Majority durability. A log entry is committed only after a majority of voting replicas have persisted it. Commit still follows log order: if a lower-LSN log entry has not reached majority, later log entries cannot be committed past it. That ordering is what lets every replica agree on the same committed log prefix after failover.
- Stable-leader optimization. Within a leader's term, all log entries share the same proposal ID, so the Prepare phase of Paxos is amortized to zero — a single RPC round-trip per commit, same shape as Raft in steady state.
The commit flow inside a single log stream looks like this:
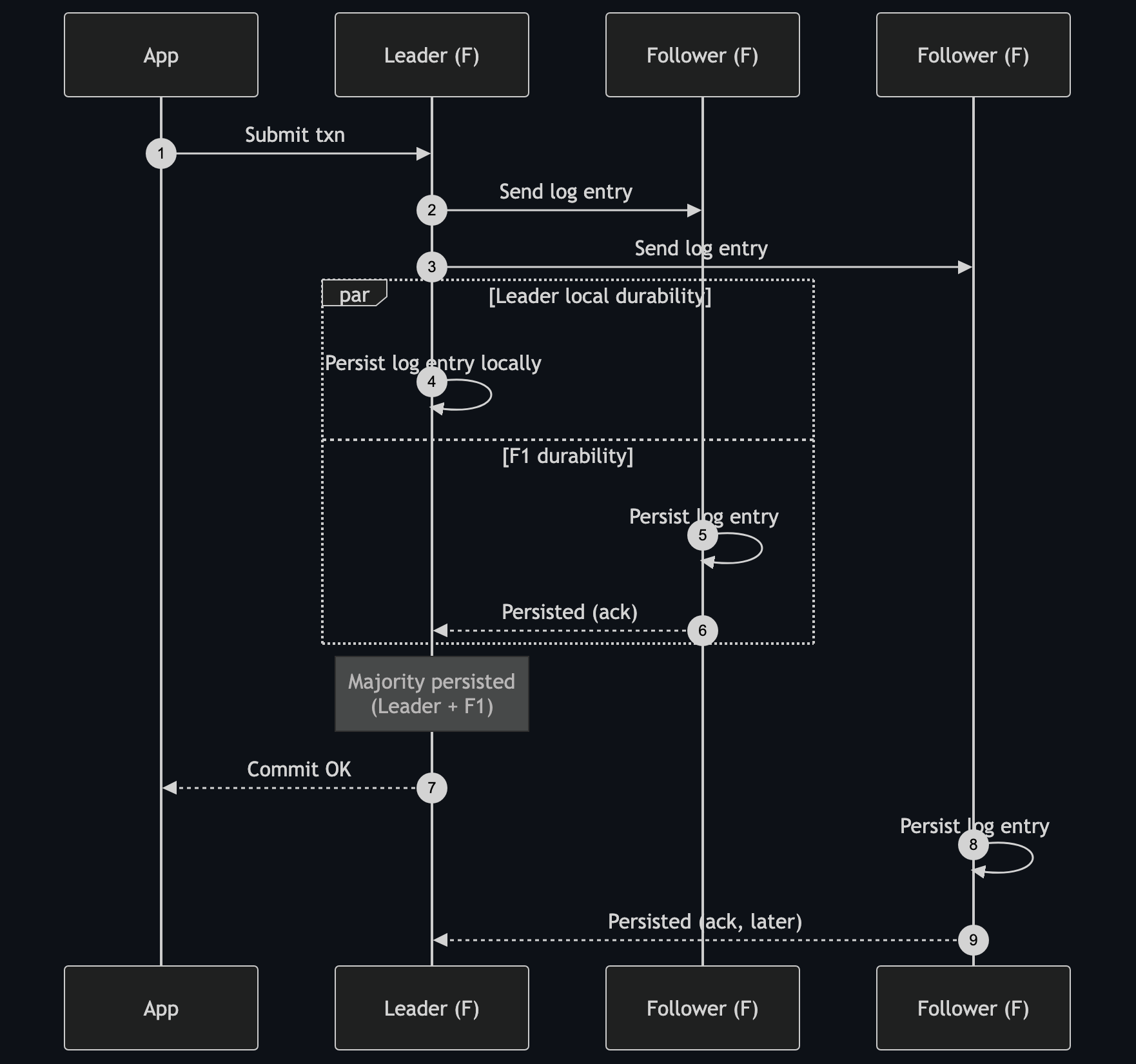
The Leader sends the log entry to followers first, then local persistence and follower persistence proceed in parallel. The transaction is acknowledged once a majority — typically the Leader plus one follower in a 3-replica setup — has persisted the log entry. A slower follower (F2 here) catches up through normal log synchronization after the commit path has already completed.
Everything that follows is a way of arranging these log streams across failure domains.
Multi-Replica Disaster Recovery
The first mechanism is the simplest: keep every replica inside one cluster and let Paxos do the work. A single cluster runs N replicas of every log stream, and a transaction is committed once PALF persists its log entry on a majority of voting replicas. If a minority of nodes fail, the surviving majority elects a new leader, updates the membership list, and keeps serving traffic — automatically, with RPO = 0 and RTO < 8 seconds.
Conceptually the RTO budget breaks into four phases, each contributing a fraction of the total. The actual numbers depend on cluster size, network latency, and timeout configuration:
| Phase | Mechanism |
| Failure detection | Lease-based heartbeat between replicas; lease expiry is the dominant contributor |
| Leader election | PALF election protocol, log-completeness-based candidate selection |
| Membership change | Atomic update of the voting member list via Paxos |
| Routing convergence | OBProxy / application connection pool refresh |
OceanBase supports three replica types, configured per tenant through locality:
- F (Full-featured) — Holds clog + MemTable + SSTable. Votes in Paxos. Can be elected Leader. The Leader serves writes and strong-consistency reads; Followers serve weak-consistency reads. Every tenant needs at least one.
- R (Read-only) — Has complete data but doesn't vote. Receives clog asynchronously as a Learner. Serves weak-consistency reads. Useful for read scale-out without inflating quorum size.
- C (Columnstore) — Same role as R for the consensus layer, but stores baseline data column-wise. Used to attach AP-style workloads to the same cluster.
A typical locality string looks like this:
ALTER TENANT prod SET LOCALITY = 'F@zone1, F@zone2, F@zone3, R@zone4';That declares three voting full-featured replicas across three zones and an additional read-only replica in a fourth zone for read scale-out.
The honest limit of this mechanism: it survives minority failure only. Lose the majority — for example, two IDCs in a three-IDC, three-replica cluster — and the cluster must stop accepting writes until quorum is restored or another recovery mechanism is used.
Arbitration-Based Disaster Recovery
Traditional databases force a binary choice. Oracle Data Guard calls it "Maximum Protection" (writes block when a standby is unreachable — service stalls but data is safe) versus "Maximum Availability" (writes continue asynchronously when standby fails — service continues but RPO drifts above zero). You pick one. The arbitration service is OceanBase's answer to that false dichotomy.
The idea: add a lightweight arbitration service (A) — a tiny process that participates in elections, Paxos Prepare, and member-change voting, but stores no data, does not participate in log majority voting (Paxos Accept), and can never become Leader. Two deployment shapes dominate:
- 4F + 1A — Two full replicas in primary IDC, two in secondary IDC, arbitration in a third. Tolerates losing either full IDC.
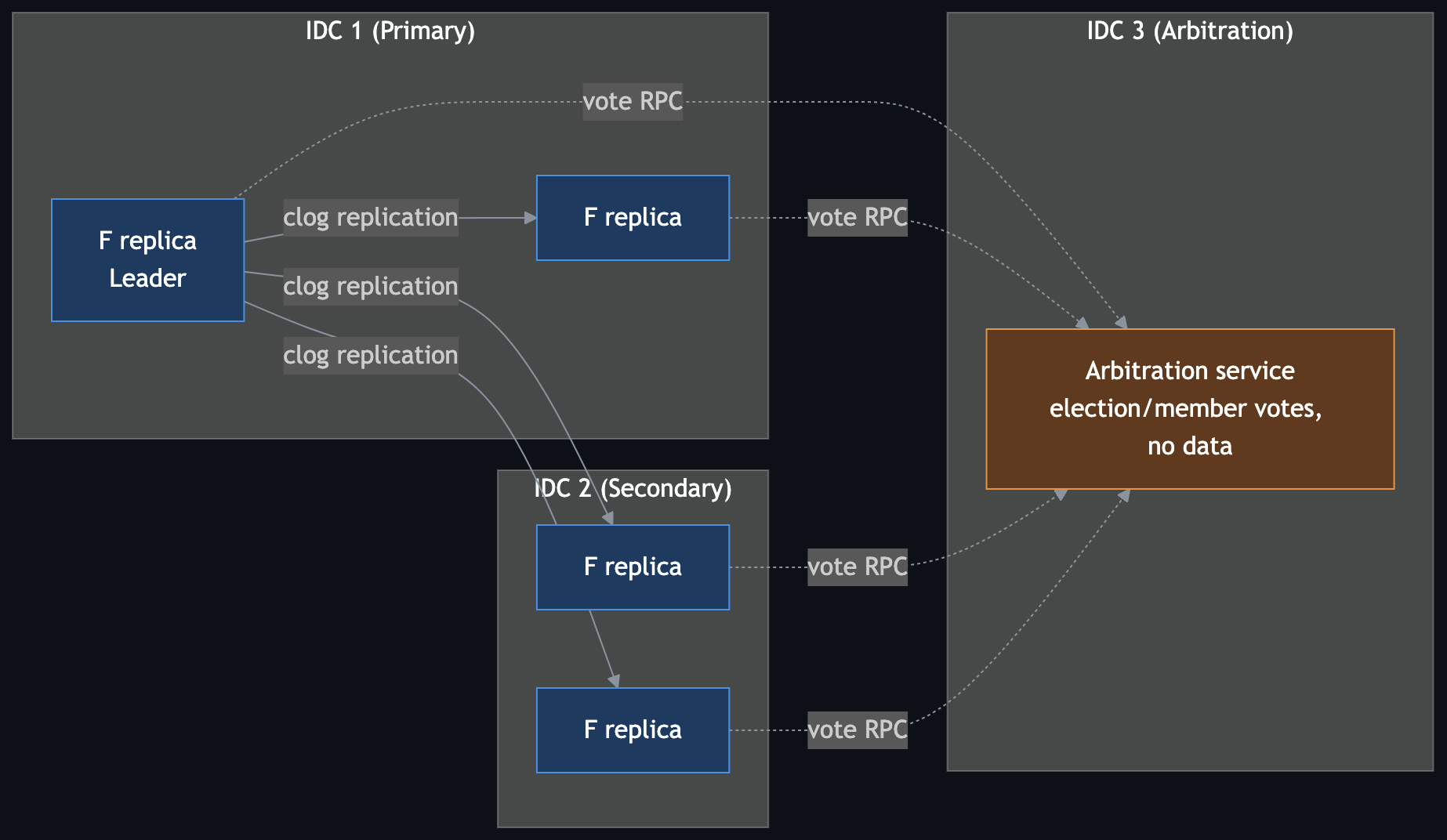
In steady state, the Leader replicates clog to follower replicas. The arbitration service participates in election and membership decisions but does not store logs or vote in the log Accept path.
- 2F + 1A — Two full replicas plus arbitration. Lowest-cost RPO=0 setup.
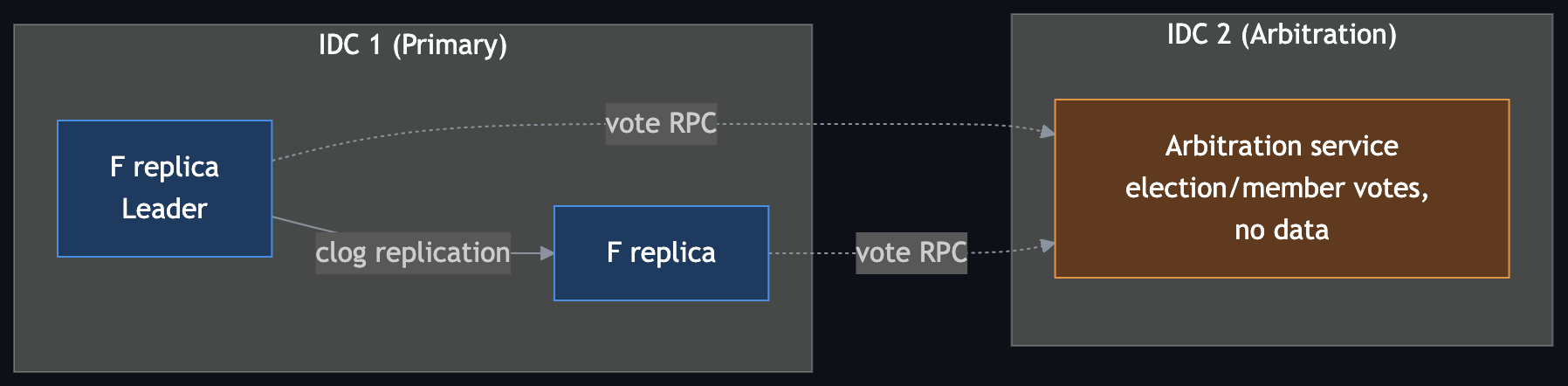
The minimum-cost RPO=0 shape. In steady state, clog flows from the Leader to the follower. Losing either F replica is survivable because arbitration can help the surviving full replica complete the election and membership-change path without storing user logs itself.
When exactly half of the full replicas fail or stop acknowledging logs long enough to cross the degradation timeout, the arbitration service can participate in an automatic degrade:
- The leader detects that some full replicas have stopped acknowledging logs for
arbitration_timeout. - The arbitration service checks whether the lagging replicas match the documented degradation conditions, such as server failure, stopped server/zone, network interruption, full log disk, or rebuild.
- The failed full replicas are removed from the member list and recorded as degraded, while the tenant locality remains unchanged.
- The remaining full replica or replicas continue serving writes — with RPO still 0 — and the degraded replicas can be added back through the upgrade flow after they recover.
The degrade behavior is controlled by arbitration_degradation_policy:
LS_POLICY(default) — Degrade the affected log stream after the degradation timeout when the documented conditions are met. Maximizes availability.CLUSTER_POLICY— Before degrading, check connectivity to the Root Service. If the leader is itself isolated from cluster metadata, don't degrade; step down so election can move leadership to a connected replica. This guards against the leader-island scenario where a partial partition could otherwise produce competing arbitration outcomes.
Split-brain is prevented structurally by the same majority-based Paxos rules that govern ordinary full replicas, plus arbitration-controlled membership changes. The arbitration service is unique per log stream, holds no data, and is barred from becoming Leader; it helps the surviving side complete election and degradation decisions without creating a second writer.
What arbitration doesn't solve: total cluster loss, or the bug-induced failure where the whole cluster crashes on the same bad input. For that, you need a separate cluster.
Tenant-Level Physical Standby
The separate-cluster answer is the physical standby. Starting in OceanBase 4.1.0, physical standby moved from cluster-level roles to tenant-level roles as an independent primary/standby architecture.
Earlier versions (3.X) tied the standby relationship to the entire cluster. Now it lives at the tenant level — one cluster can host a mix of primary tenants and standby tenants belonging to entirely different primary sources. Cluster topology and DR topology are decoupled.
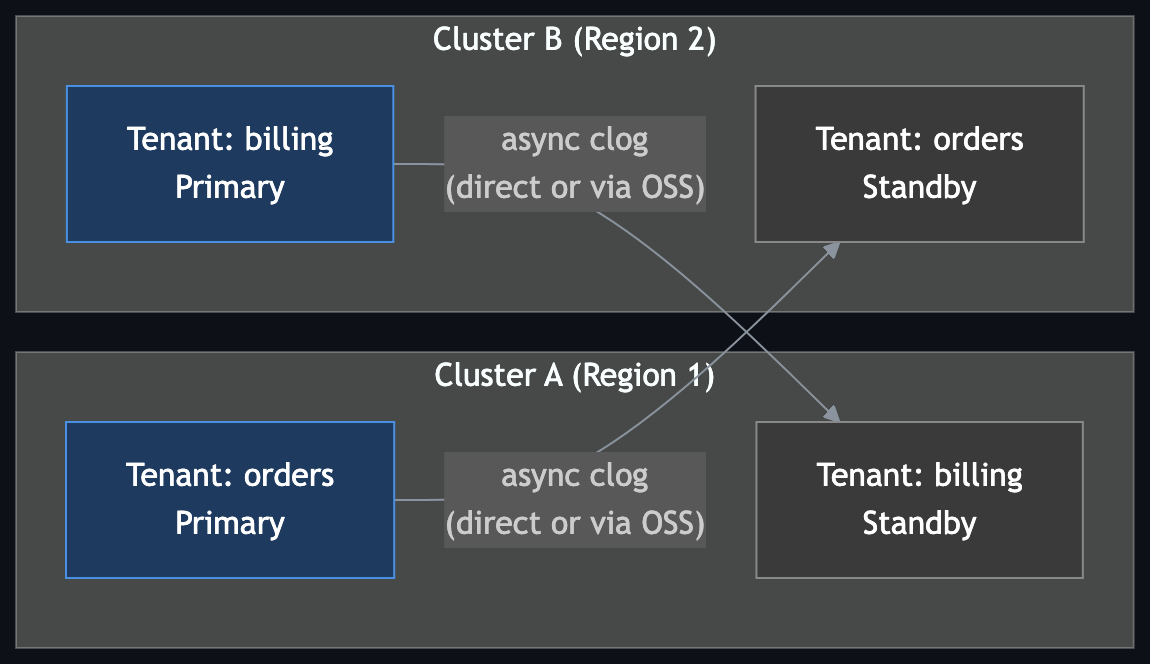
- Direct network transport — Standby pulls clog directly from the primary over TCP. Lower operational footprint.
- Log archive / shared-storage transport — The primary archives clog to a storage medium such as NFS or OSS, and the standby reads from that archive. This is useful when network paths between clusters are restricted.
Either way, log shipping is asynchronous, and only Maximum Performance mode is supported. V4.4.2.1 introduces Maximum Protection or Maximum Availability modes for physical standby as experimental capabilities, with production readiness expected in V4.4.2.2. For release lines where only Maximum Performance is production-ready, synchronous zero-RPO protection remains an intra-cluster quorum design problem handled by multi-replica disaster recovery or arbitration-based disaster recovery.
Switching between primary and standby comes in two flavors:
- Switchover (planned) — Drain primary writes, wait for standby to catch up, swap roles. RPO = 0.
- Failover (unplanned) — Primary is gone; promote the standby with whatever clog it has. RPO > 0, bounded by replication lag at the time of failure.
Physical standby is the right answer when the failure you're worried about is bigger than a single cluster can contain — a regional outage, a software defect that crashes every node on the same code path, or a logical corruption you want to wall off behind asynchronous replay.
Choosing the Right Mechanism
The three mechanisms are stackable, not exclusive. A typical production deployment looks like this:
| Failure domain | Mechanism | RPO | RTO | Cost |
| Minority node / single IDC | Multi-replica (3F or 5F) | 0 | < 8s | Standard |
| Half-cluster failure, cost-sensitive | Arbitration (4F+1A or 2F+1A) | 0 | < 8s | Lower than full-quorum equivalent |
| Total cluster loss, regional disaster, software bug | Physical standby | > 0 (lag-bounded) | Operator-driven | Second cluster |
The pattern most enterprise OceanBase deployments converge on: arbitration-based deployment inside the primary region for cost-efficient RPO=0, plus a physical standby in a distant region as the last line of defense.
Try It Yourself
The OceanBase Community Edition lets you stand up a three-replica cluster on a single machine in about ten minutes — long enough to kill a node and watch the eight-second RTO budget for yourself. That hands-on minute of staring at a recovered cluster is worth more than any architecture diagram.
Further Reading
- High availability overview — OceanBase Docs
- Replica introduction — OceanBase Docs
- HA deployment solutions for OceanBase clusters



Keep Reading
View all posts
From Complex to Simple: How We Built seekdb for the AI Era
AI era doesn't need another heavy, complex enterprise database. It needs agility. It needs flexibility. We went back to the drawing board to understand what an AI application actually needs from a database. Our answer is OceanBase seekdb



Beyond Fine-tuning: Solving DABstep's Hard Mode with Versioned Assets
On the DABstep Global Leaderboard, OceanBase DataPilot agent has secured the top spot, maintaining a significant lead over the runner-up for a month. The secret to our SOTA results was a fundamental shift in engineering paradigm: moving from "Prompt Engineering" to "Asset Engineering."


Permanent Server Offline in OceanBase: How the Cluster Heals After a Node Is Gone
How OceanBase distinguishes a transient outage from a permanent loss, and why operators should intervene rather than wait for the automatic re-replication timer.
