
Meet OceanBase AI Database, the unified database for operational data, real-time analytics, and AI. Explore ->
Meet OceanBase AI Database, the unified database for operational data, real-time analytics, and AI. Explore ->
OceanBase Failover Routing: How OBProxy and Leader Scheduling Carry RTO < 8s Toward the Client

- "RTO < 8s" is two recoveries running in parallel: the cluster electing a new Leader, and the routing layer catching up to it. The application feels the slower of the two, plus any client-side timeout or connection handling.
- The catch-up is passive by design — stale routes are corrected by request-path feedback, Location Cache refresh, and bounded retry or remote execution. In the common case, the application sees delay rather than topology.
- OBProxy extends that same passive discipline outward, with three access-control mechanisms (state, detect, alive-unavailable) covering the failure modes where passive refresh alone would loop on a dead route.
What's the RTO of OceanBase? Under 8 seconds. What happens to your application during those 8 seconds? That's a longer answer — and most HA writing doesn't try, leaving the path between the new Leader and the client as an exercise for the reader.
Between the new Leader and the application sit two route caches and a TCP connection, and how they recover decides whether your application sees 8 seconds of slight delay or 8 seconds of failed queries in the log. This post follows one SELECT through a Leader death, from the moment the lease fails to the moment the result comes back.
Two Recoveries Behind "RTO < 8s"
A Leader-side failure starts two recoveries at once.
Cluster recovery is what the SLA measures. Followers detect a stale lease, run a Paxos election, a new Leader registers itself. This is fast — sub-second to a small handful of seconds — because it's all internal RPC inside the cluster, and the algorithm doesn't need anyone outside to participate.
Route recovery is the one that's easy to forget. Any component that cached the old Leader can keep using that stale route until it notices. The application sees whichever recovery finishes last.
The interesting design question isn't how to make either recovery fast in isolation. It's how to keep route recovery from ever needing cluster recovery's full attention. To see how, we first need to know what's in that routing chain.
The Routing Chain in Steady State
In a healthy cluster, a SQL travels a short path. The application opens a MySQL-protocol connection to OBProxy — the client-facing proxy that sits between drivers and OBServers. OBProxy parses the SQL, looks up which log stream (LS) owns the affected tablet, consults its Location Cache to find the OBServer hosting that LS's Leader, and forwards the request.
If the request lands on an OBServer that isn't hosting the Leader — say, because the cache is slightly stale, or because the OBServer was picked for a different reason — that OBServer consults its own Location Cache to figure out where the Leader actually is, and forwards. Inside the cluster as much as at the edge, every node holds the same kind of map: LS → which OBServer hosts the Leader, by replica role.
Two caches, then, sit between the application and the data: OBProxy's, and the OBServer's. When the Leader dies, both are wrong. The question becomes: what specifically dies first, and what does the cluster do about it?
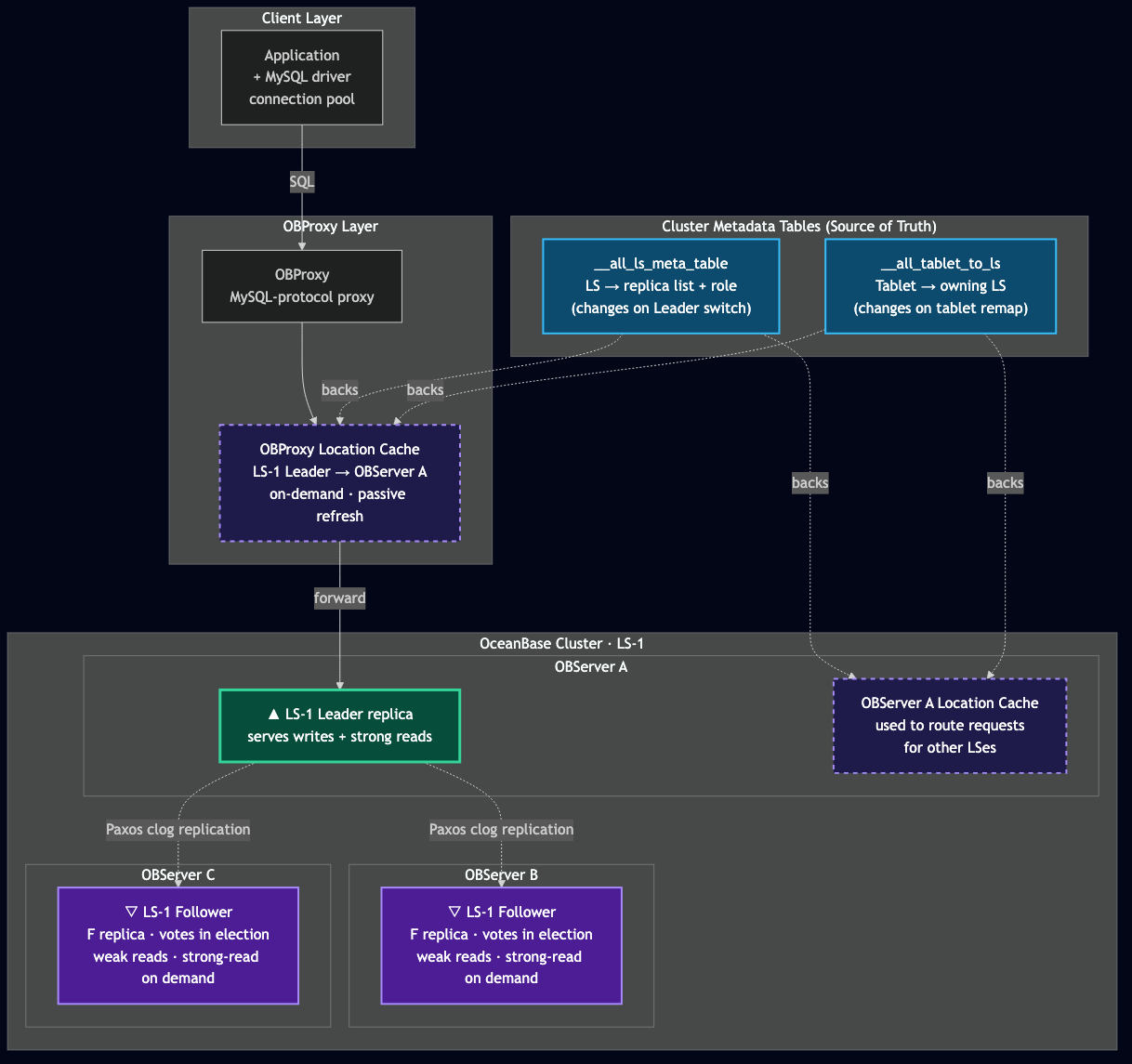
Diagram 1 — The routing chain in steady state. Metadata such as LS location and tablet-to-LS mapping backs the route caches; those cached routes can be stale the moment the Leader on OBServer A dies.
What Breaks First: Lease, Step-down, Election
The first thing to fail is the lease.
A Leader holds its position via a lease that it must renew, by heartbeat, against a majority of Followers. As long as renewal succeeds, the Leader is the Leader. When a Leader can't gather a majority for a renewal — its network is partitioned, its host is hung, the OBServer process is gone — the lease expires on its own timeline. In an ungraceful failure, the old Leader doesn't get to send anything; it simply stops being the Leader once followers' lease tracking crosses the timeout threshold. Followers whose own lease tracking has timed out start their own takeover attempts.
A takeover attempt that gathers a majority becomes the new Leader. The picks aren't random: the election service ranks eligible candidates by a documented priority — user-specified Leader, then Primary Zone — with server and zone state acting as eligibility filters above that. A node in a stopped zone, or one already marked offline, doesn't enter the race at all. That ranking gives the cluster a stable preference for leadership placement; the routing layer still converges through location-cache refresh and server feedback, rather than by guessing the winner.
One subtlety carried over from the previous posts: only F replicas vote and can become Leader. R and C replicas are read-oriented followers: they do not participate in election or log voting, and they cannot be elected as the log stream's Leader. The candidate set is exactly the eligible F replicas in the log stream's member list, ranked by the priorities above.
When the new Leader is installed, the authoritative LS location metadata changes. What does not happen is a blanket push to every route cache that might hold the old answer.
Which leaves any cache that had touched that LS — inside the cluster or at OBProxy — still pointing at the old Leader until it refreshes.
The Stale Chain Problem: Push or Pull?
There are two ways for those caches to converge on the truth, and the choice between them is the actual hinge of this post.
Push updates each cache as soon as the Leader changes. Every restart, every planned switchover, every zone isolation fires updates fanning out to every cache that might care. The cost of routing recovery scales with operational events: even caches that wouldn't have touched the affected LS for the next hour pay the synchronization cost.
Pull lets each cache discover its own staleness on first miss. The cost scales with demand: only caches that actually try to use the stale entry pay anything. Caches that don't touch the affected LS pay nothing at all.
OceanBase picks pull. The argument is simple: in a healthy cluster, Leader-affecting events happen often enough — every node restart, every minor maintenance, every Locality change — that push would generate cache traffic in proportion to operational activity rather than query load. Pull amortizes the cost onto the queries that actually need the answer.
But pull only works if the request that lands at the stale location can be told it's wrong, and if something can be done about it without the application noticing.
How Pull Works: Passive Refresh and Internal Retry
The mechanism rests on two pieces of metadata, which together describe where a request should go:
| Table | What it maps | Changes when |
| __all_ls_meta_table | LS → replica list, with role (Leader / Follower) per replica | Leader switches; replica membership changes |
| __all_tablet_to_ls | Tablet → owning LS | Tablet remap (transfer, partition reorganization, etc.) |
The two are treated differently on purpose. Tablet remaps are rare, structural events — eagerly propagating or invalidating them is cheap relative to the disruption they'd cause if missed. Leader switches are common — every restart and switchover can trigger one — so LS leader location is typically corrected through passive refresh and route feedback.
Passively means: a request lands at a cached route, the receiving OBServer discovers that the expectation and the actual replica role do not match, and the route miss is fed back through the execution result so the cache can be refreshed. OBServer location cache can refresh by lightweight RPC or by SQL over Meta tables; OBProxy can then update its own cache from the information returned by OBServer.
The same discipline plays out at two layers. Inside the cluster, when an OBServer receives a strong-read or write request for a replica that is no longer the Leader, it can route the request to the correct OBServer — either by forwarding or by remote execution — with an extra network hop. At OBProxy, the OBServer's result or error packet can carry route-update feedback, telling OBProxy that its Location Cache is stale. Two different surfaces, one rule: the system uses the request path itself to repair stale routes.
That last clause is what makes "RTO reaches the client" more than an internal election number. In the common case, the application sees a slower SQL rather than a topology change. It is not an unconditional guarantee, though: retry is bounded by query timeout, retry timeout, connection state, and transaction state.
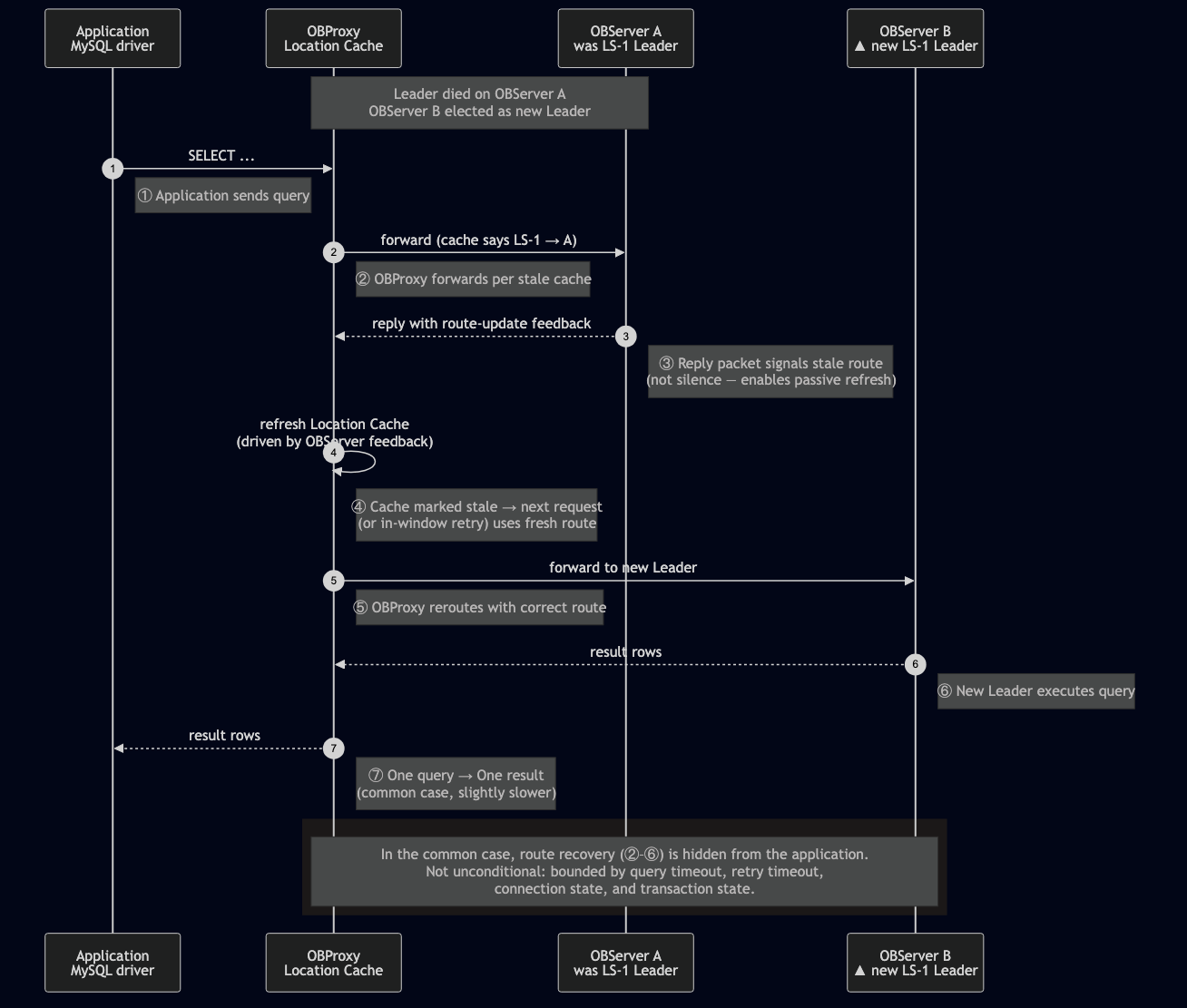
Diagram 2 — The passive-refresh sequence. In the happy path, the application sends one SQL and receives one result; everything between steps ②-⑦ is OceanBase recovering the route before the caller has to reason about topology.
This works when the cached route still reaches a responding OBServer. But what if the OBServer is dead, or the network to it is partitioned? Then there's no reply at all to drive the refresh — and the closer you get to the application, the more often that happens.
OBProxy: When Pull Isn't Enough
Inside the cluster, a wrong OBServer is still a responding OBServer. Across the network to OBProxy, a dead host can fail to respond entirely, and passive refresh has nothing to work with — there's no "not leader" reply to trigger it. So OBProxy adds a layer that internal Location Caches don't need: liveness tracking.
| Blacklist | Source of truth | Trigger | Key params |
| State | Polled from Root Service views | INACTIVE / REPLAY enter the state blacklist; DELETING / DELETED update the server list; UPGRADE is not blacklisted but is treated as non-routable | Driven by RS heartbeat (lease_time, default 10s) |
| Detect | OBProxy probes sys tenant directly | select 'detect server alive' from dual times out 3 consecutive times at 5s each | On DETECT_DEAD, OBProxy closes all open connections to the server |
| Alive-unavailable | Real SQL outcomes | congestion_failure_threshold failures (default 5) within congestion_fail_window (default 120s) | congestion_retry_interval (20s), min_congested_connect_timeout (100ms) |
The three are intentionally redundant. State catches what Root Service already knows. Detect catches network partitions where RS still thinks the server is fine but OBProxy can't reach it. Alive-unavailable catches in-flight degradation that neither of the first two has noticed yet. If a server is covered by any of these controls, OBProxy filters it from normal routing — with one important escape hatch: if every candidate is blacklisted, OBProxy can force a retry against a blacklisted server rather than declare that no route exists.
Note: Parameter defaults shown are representative for OBProxy 4.x. Verify against your deployment's documentation, as thresholds may differ by version and configuration.
The blacklists don't replace passive refresh; they complement it. Passive refresh handles "you sent me to the wrong replica." The blacklists handle "you sent me to a replica that can't answer at all."
The Timeline, End to End
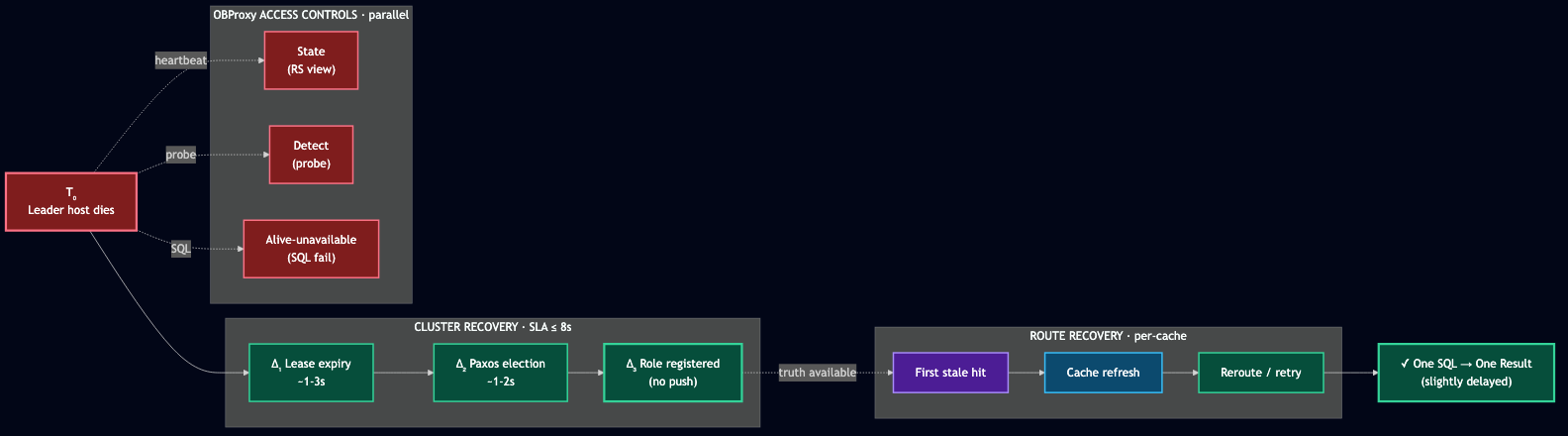
Diagram 3 — Two recoveries running concurrently. Cluster recovery carries the < 8s SLA; route recovery is paid per-cache on first stale hit, plus OBProxy's parallel blacklist entry.
The SLA covers cluster recovery — Δ₁ + Δ₂ + Δ₃, documented as "under 8 seconds" in Database-level HA. Route recovery is paid per-LS, per-cache, on the first stale hit — a single extra round-trip per cache, plus whatever the OS connection-reset delay is for clients that were holding open connections to the dead host.
Where the Bounded Contract Ends
The contract covers a lot — but not everything. Three failure modes sit at its edge, and the application still owns them:
- Connection-pool reset semantics. If your app holds a TCP connection to OBProxy that was multiplexed onto the dead OBServer, that connection may receive RST or hang briefly while OBProxy reroutes. Most pools handle this by recycling the connection on the next failure; verify yours does, and that "next failure" doesn't mean "five seconds of waiting first."
- Idempotency of in-flight transactions. Single-statement requests are the easiest to absorb through reroute or retry. Multi-statement transactions that were open on the old Leader can roll back — the retry mechanism does not make an in-flight transaction magically replayable. Application retry logic for transactions should already be idempotent for any number of reasons; this is one more.
- Client-side query timeouts. If your driver's timeout or
ob_query_timeoutis shorter than the cluster's RTO budget, you'll see failures even when the database recovered fine. Set timeouts against your HA SLA, not the other way around.
The route feedback and retry path are what make "RTO < 8s" mean something outside the cluster. Cluster recovery and route recovery have to converge — the lease-and-election sequence completing, and every hot Location Cache between the new Leader and the application catching up — before the result comes back. That convergence is what every section above has been a detail of. Get the database side right, and the application side is mostly a matter of not getting in the way.
For covered minority-failure scenarios, the cluster is designed to keep its end of the < 8s. The driver has to keep its.
Further Reading
- High availability overview — OceanBase's HA model, RPO=0, and RTO < 8s
- HA deployment solutions — supported topologies from 3-IDC to cross-region
- Replica introduction — F, R, C, and arbitration replica types
- Arbitration service — cost-efficient RPO=0 with 2F1A or 4F1A (Enterprise Edition)



Keep Reading
View all posts
From Complex to Simple: How We Built seekdb for the AI Era
AI era doesn't need another heavy, complex enterprise database. It needs agility. It needs flexibility. We went back to the drawing board to understand what an AI application actually needs from a database. Our answer is OceanBase seekdb



Beyond Fine-tuning: Solving DABstep's Hard Mode with Versioned Assets
On the DABstep Global Leaderboard, OceanBase DataPilot agent has secured the top spot, maintaining a significant lead over the runner-up for a month. The secret to our SOTA results was a fundamental shift in engineering paradigm: moving from "Prompt Engineering" to "Asset Engineering."


Permanent Server Offline in OceanBase: How the Cluster Heals After a Node Is Gone
How OceanBase distinguishes a transient outage from a permanent loss, and why operators should intervene rather than wait for the automatic re-replication timer.
