
Meet OceanBase AI Database, the unified database for operational data, real-time analytics, and AI. Explore ->
Meet OceanBase AI Database, the unified database for operational data, real-time analytics, and AI. Explore ->
From High Availability to Business Continuity: What Global Systems Actually Need


Most enterprise teams have high availability configured. Far fewer have business continuity tested.
That gap matters more than it used to. Data sovereignty requirements are pushing workloads into regions that were once optional. Shared control planes mean a regional event can cascade further than the architecture diagram suggests. And the failure modes that actually threaten business continuity — power grid disruption, subsea cable damage, provider-level outages — sit outside the multi-AZ availability model entirely. The question is no longer whether your database is highly available. It's whether your business can continue when a region, a control plane, or a provider-level dependency goes down.
Four levels of failures
An availability architecture typically addresses up to four failure scopes. Most teams are well-covered at Levels 1 and 2. The gap between "highly available" and "business continuity" opens at Level 3.
| Level | Failure scope | What DR requires | CockroachDB | Spanner / AlloyDB | Aurora | OceanBase |
| 1 | Node | Redirect to surviving replica | Automatic (Raft) | Automatic (Paxos) | Automatic (storage-layer) | Automatic (Multi-Paxos) |
| 2 | Datacenter / AZ | Quorum across physically separated replicas | Multi-AZ default | Multi-AZ default | Multi-AZ default | Multi-AZ; 2F+1A option reduces storage cost |
| 3 | Region | Replicas in a second geographic region | Multi-region native (added write latency) | Synchronous replication (Google Cloud only) | Async replication; RPO>0 for unplanned failover | Synchronous or async replication |
| 4 | Cloud provider | Independent control plane and infrastructure | Cross-cloud for self-hosted clusters (user manages cross-cloud networking); managed cloud is single-provider per cluster | Google Cloud only | AWS only | Runs on 7 clouds with independent control plane; provider outage doesn't block failover |
At Level 3, the approaches diverge: Spanner and OceanBase offer synchronous multi-region with RPO=0; CockroachDB supports multi-region with configurable consistency; and Aurora Global Database provides async replication with RPO>0. The sharpest differentiation is at Level 4 — where control-plane independence and managed cross-cloud operations determine whether a provider-level outage disrupts your recovery.
The transitions that matter
Why level 2 doesn't cover level 3
Three gaps recur when teams honestly audit their DR posture:
Fault isolation is weaker than the diagram suggests. Control planes, IAM dependencies, rate limits, and service orchestration layers aren't always isolated the way application teams assume. When the provider has a bad enough day, "independence" between AZs becomes less real than it looks on the architecture slide.
"Can fail over" and "will fail over cleanly" are different things. A database cutover touches DNS, connection routing, TLS certificates, IP allowlists, secrets, dependency configuration, application reconnect behavior, and operational authority. A diagram that looks clean on paper can still become a multi-hour incident if any one of those steps fails under real pressure.
Runbooks decay faster than teams expect. Infrastructure changes. Teams rotate. Ownership transfers. A DR plan written against last year's topology, tested once during an off-peak weekend, and never exercised again is not a current capability. It's a historical artifact.
Continuity can't be measured by architecture alone. It has to be measured by drills.
How OceanBase addresses DR for each level
OceanBase's availability architecture was designed for Levels 1–4 from the start, not added as an afterthought. Here's how each level works — and where the current trade-offs are.
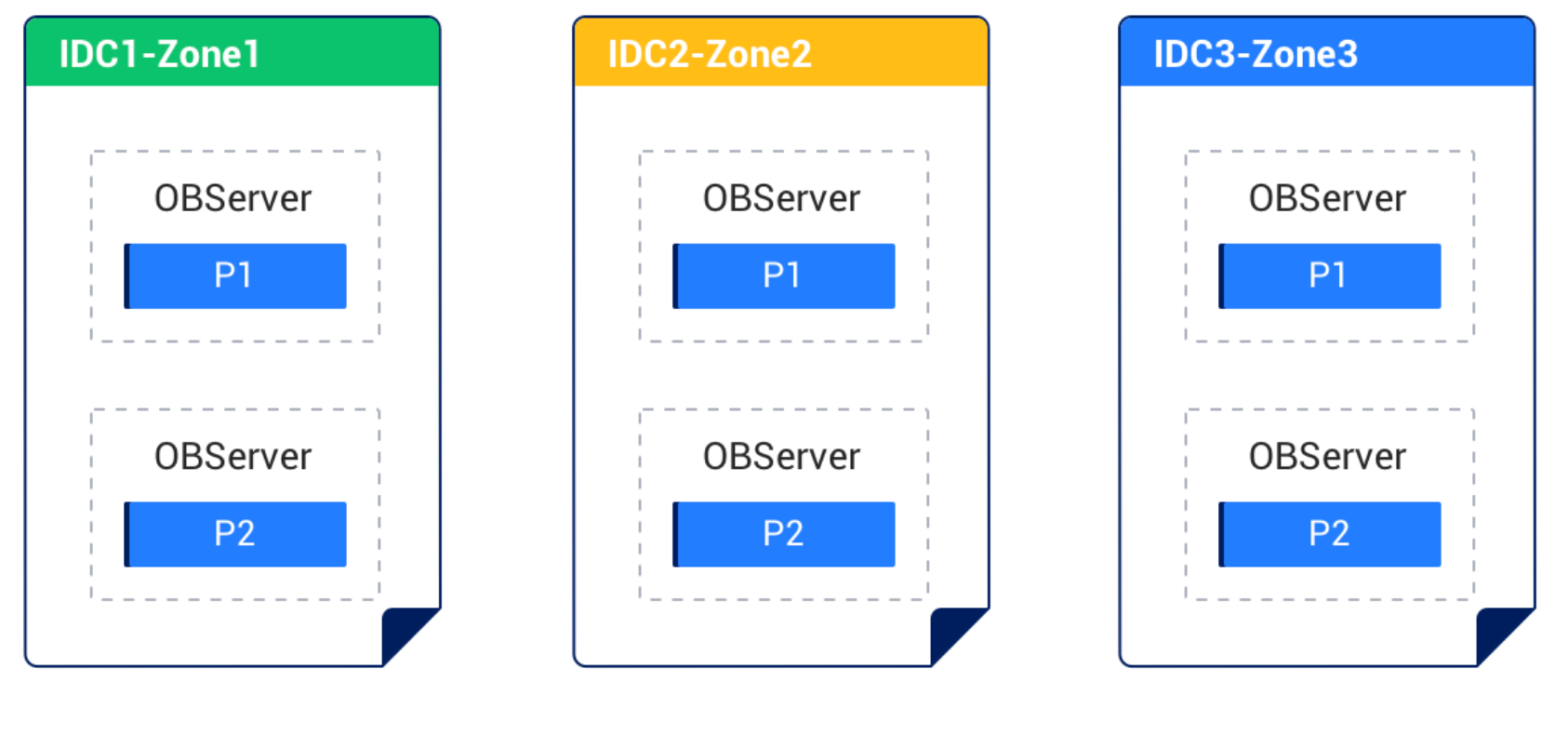
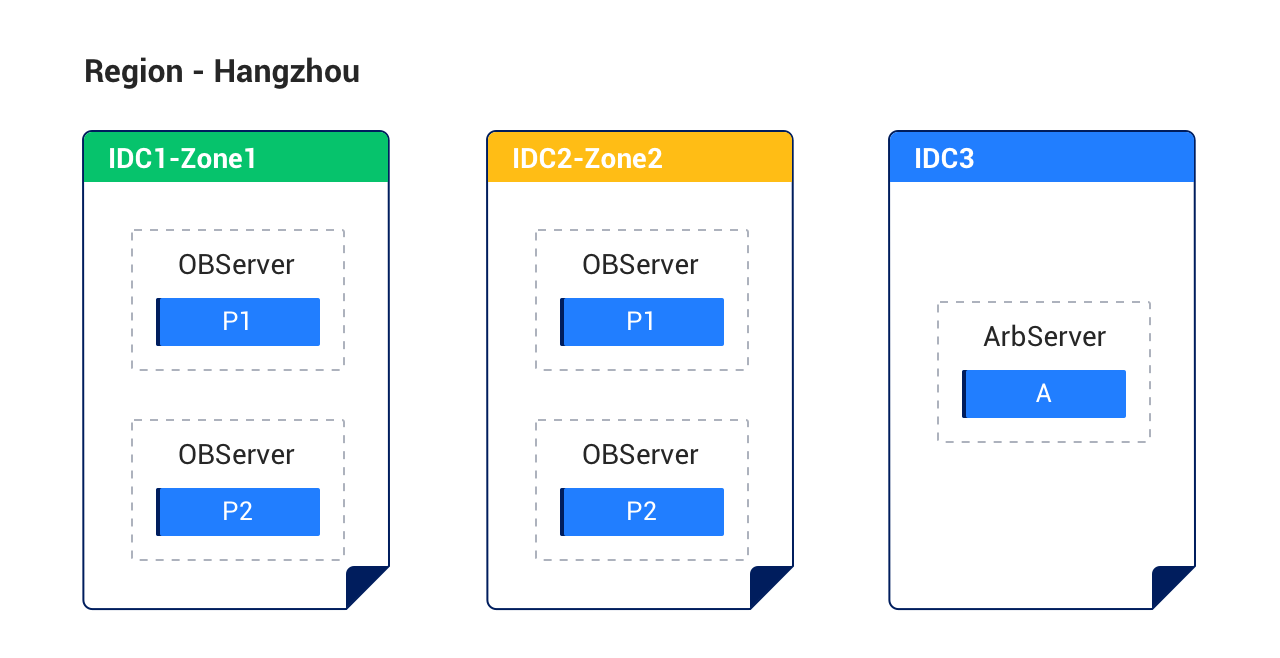
Level 3 (Region failure): OceanBase supports both synchronous and asynchronous cross-region replication. With synchronous replication, committed transactions are guaranteed to exist in both regions before acknowledgment — RPO=0 under normal network conditions. The trade-off is - synchronous cross-region replication adds write latency proportional to the network round-trip between regions.
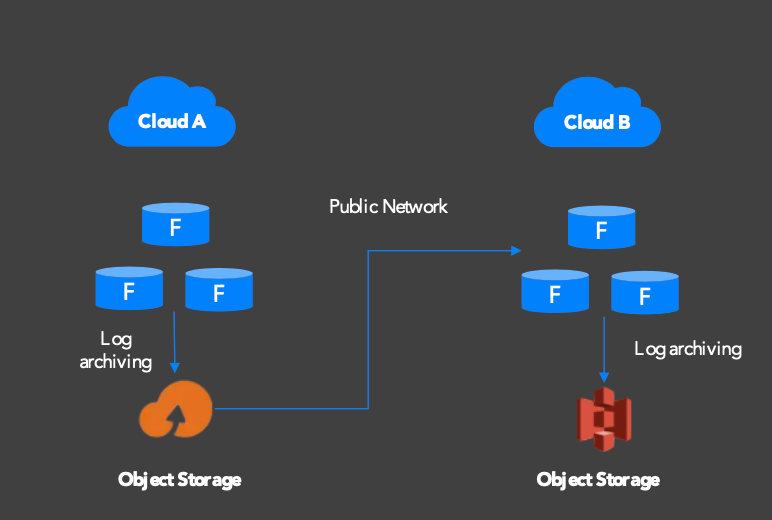
Cold standby (async replication, lower cost):
Warm standby (sync replication, RPO=0):
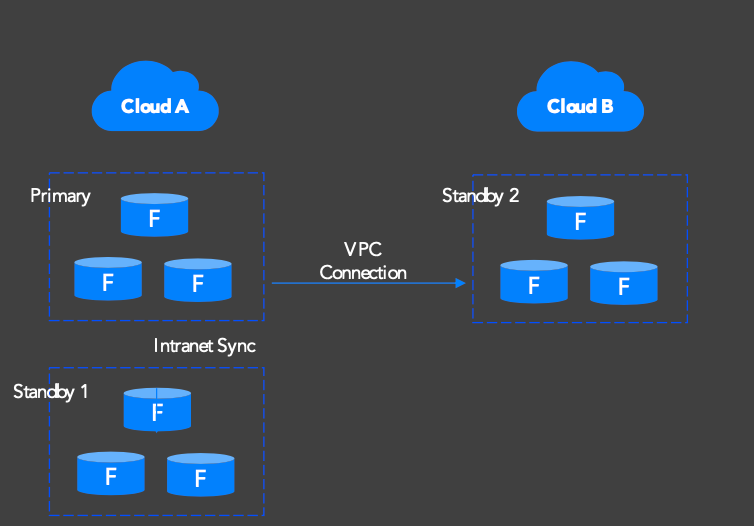
Level 4 (Cloud provider failure): OceanBase Cloud runs on seven major public clouds with an independent control plane. Cross-cloud standby configurations replicate data via OceanBase Migration Service (OMS) with near-real-time sync. If one cloud provider experiences a control-plane outage, OceanBase Cloud can still manage failover to a standby cluster on another provider.
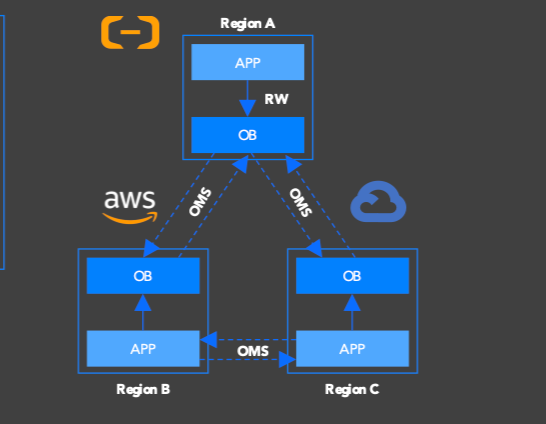
The architecture isn't tied to a specific cloud's replication primitives. This is what makes cross-cloud DR possible without application changes.
Where to start
If you're making a platform decision — not reacting to a single incident — this sequence works:
Make cross-region real first. Pick the workloads that matter. Define RTO and RPO in writing. Run drills until you can hit those numbers consistently. This is Level 3 coverage, and it addresses the most common gap.
Add cross-cloud cold standby as the vendor backstop. This is the lowest-cost way to eliminate the total-loss scenario — Level 4 coverage at minimal operational overhead.
Upgrade only the systems that justify tighter coverage. Move truly critical services to warm standby or cross-cloud primary/standby when the business value justifies the cost and latency trade-offs.
The most common failure pattern is skipping step one — jumping straight to "multi-cloud" and then discovering that the cutover process is still manual, still brittle, and still unproven.
Five things to verify before your next DR review
Before the next review, confirm these with evidence, not assumptions:
Two governance principles matter here. First, define when the clock starts and what "recovered" actually means for RTO/RPO measurement — teams frequently disagree on this during an actual incident. Second, require proof. If you can't produce drill logs from the last end-to-end exercise, you don't have a tested recovery objective. You have confidence without evidence.
What's next
OceanBase Cloud supports cross-region and cross-cloud DR — from cold standby to full primary/standby with transparent failover. Create your OceanBase cluster now to test your cutover assumptions against real infrastructure.
This is the first in a six-part series on multi-cloud disaster recovery. Stay tuned to dive deep into multi-cloud high availability capabilities of OceanBase.
Download The Multi-Cloud DR Playbook to learn how cross-cloud database architectures reduce provider-level risk.



Keep Reading
View all posts
Exploring OceanBase 4.3: New Features and Enhancements
At the OceanBase DevCon 2024, we introduced the OceanBase 4.3.0 Beta, unveiling a brand new columnar engine. This release achieves near petabyte-scale, real-time analytics in seconds, and enhances the integration of TP and AP capabilities.



How seekdb M0 Gives OpenClaw Persistent Memory and Shared Experience
OpenClaw's memory degrades over time—an architectural limitation, not a configuration issue. seekdb M0 solves this with cloud-based memory that persists across sessions and shares learned experience across agents.


Deploy and Run OceanBase from Qoder Desktop in One Sentence
See how the OceanBase plugin for Qoder Desktop handles host checks, deployment, verification, lifecycle operations, and ecosystem components.
