
Meet OceanBase AI Database, the unified database for operational data, real-time analytics, and AI. Explore ->
Meet OceanBase AI Database, the unified database for operational data, real-time analytics, and AI. Explore ->
Rethinking the Database for the AI Era
- Models may define AI’s capability boundary, but business value depends on whether enterprises can turn their data into real-time, trusted, and actionable context.
- AI breaks two old database assumptions. The primary user is no longer only human but increasingly an agent, and the data that matters is no longer only structured but also documents, text, images, audio, video, logs, and vectors.
- An AI database must unify multimodal data, real-time transactions, hybrid search, agent-native primitives, and open architecture in one consistent foundation.
Over the past three years, the most striking story in technology has been the leap in AI capabilities — models that iterate week by week, learning to reason, generate, and understand language. Enterprises have answered with their wallets, driving a massive surge in AI investment directed at both the models themselves and the underlying compute power.
But there's a B-side. The spending climbs; the business value doesn't keep pace. Gartner predicted 60% of AI projects will be abandoned for failing to meet production requirements — most often for a lack of high-quality data. Between a model's general intelligence and the intelligence an enterprise actually needs lies a gap of business context. Closing it is, at bottom, a data problem. The next generation of enterprise AI will not be limited by model intelligence alone. It will be limited by whether enterprises can turn their data into real-time, trusted, and actionable context.
This brings me to the question I've spent the past year on, and the real subject of this piece: in the age of AI, what should a database become — what must change, and what must be inherited.
Two assumptions just broke
For decades, a database rested on two assumptions: that its user was a person — someone writing SQL or reading a dashboard — and that the data worth managing was structured, in tidy rows and columns. AI broke both at once:
- The user is no longer just human. It is increasingly an agent — software that runs continuously, calls tools, reads and writes data, holds state, and acts at machine speed. Gartner expects 33% of enterprise applications to embed agentic AI by 2028, up from less than 1% in 2024
- The data is no longer only structured. Roughly 80% of enterprise data is unstructured — documents, messages, images, audio, video, logs — and AI has, for the first time, made it computable rather than mere archive.
Neither is a simple feature request. Each break asks the database for something it was never designed to give.
What an agent demands
An agent is a new kind of data consumer — it runs around the clock, calls data on its own, and gets better by trial and error. A year of building for them has surfaced three demands no human user ever made.
- Scale — but not the scale you think. Database scalability used to mean making one database bigger. The agent era inverts the problem. When generating an application costs almost nothing, their number explodes. Ant's Lingguang, a consumer platform that turns a prompt into an app, already carries some 30 million of them. Each holds little data, most stay dormant, and any may need to wake in an instant. Give each its own resources and the cost is impossible; let them share blindly and the data boundaries collapse. So "massive" now means a massive number of small databases, not one large one — millions that must coexist cheaply, stay isolated, scale on demand, and fall to near-zero when idle. Few traditional databases were designed for this pattern: millions of small, isolated, mostly dormant data environments that must wake instantly and scale cheaply.
- Context — the ceiling on every agent. An agent's primary workload is essentially search. From processing natural language to driving foundational components like RAG and Memory, agents constantly search and retrieve data to build context. When this retrieval must span both structured and unstructured data simultaneously, hybrid search becomes a strict necessity. The ability to return accurate context in a single recall determines whether an agent can support production-grade workloads in scenarios like risk management, AI commerce, and investment research. Ultimately, an agent's ceiling is defined not just by the model, but by its capacity to build high-quality context.
- Evolution — room to try and fail. An agent stays accurate only by iterating — finding bad cases, fixing them, re-evaluating — and each evaluation may rewrite data, change a flow, or swap a strategy. None of it can touch the running system, yet a faithful test needs a full copy of the agent's data, memory and context included — slow and heavy on a database built for stable storage rather than constant experiment. What an agent needs instead is a data environment that works like a code repository: branch on demand, experiment in isolation, merge what works, discard what doesn't. For an agent, that is the precondition for getting better.
Scale, context, and evolution each pull on a different dimension — cost, accuracy, and efficiency. An agent-friendly data foundation is one that holds all three at once, instead of buying one at the expense of another.
What the new data demands
If those three demands are about how an agent uses data, three more are about the data itself — how it's shaped, how it moves, and how we reach it.
- Form — from cost center to computable asset. Most of an enterprise's core records are structured, but most of its data is not — documents, emails, recordings, video that used to sit in archives, queried after the fact if at all. As Jensen Huang put it at GTC, "unstructured data is the context of AI" ; the mirror is just as true — structured data is the context of the enterprise. AI finally makes that unstructured half computable, but storing it isn't enough and indexing it isn't either: it has to be managed, governed, and queried alongside structured data on one foundation, with hybrid retrieval — scalar, full-text, and vector — built into the data layer rather than rebuilt by every application.
- Flow — from one-way pipeline to closed loop. Software is changing character: programs improved when someone shipped new code; agents improve when data flows back to them — outputs settling into samples, labels, embeddings, and policy, then returning as fresh context. That loop is the data flywheel, and it's what makes an application sharper with use. Today's architecture blocks it: online databases, offline warehouses, and training platforms sit in separate systems linked by slow ETL, so a problem surfaced online today is fixed only tomorrow. The loop closes only when online serving and offline analysis run on the same data, not two systems that reconcile overnight.
- Interaction — from SQL to semantics. For decades the way in was SQL: an engineer writes a query, the database returns rows. Now agents reach data through natural language and intent, which asks the database to do more than store and retrieve. Schema and relations were once the whole of its "understanding"; for an agent to grasp what the data means — and act on it — the foundation now needs a semantic layer: the business entities, relationships, metrics, and policies that connect raw facts to the business they describe.
Form, flow, interaction — together they hand the data layer a job it never had before.
From system of record to context layer
Put both shifts together, and what a database is for has changed. It is no longer only a system of record; it is becoming the context layer for AI — the place an agent turns to assemble what it knows before it decides or acts. That is the real reframing. And it sets up the question I find most important, and most often gotten wrong: if the database is becoming all of this, what about it must not change?
The constant: AI makes the bottom lines matter more, not less
Whenever a "new category" appears, the temptation is to assume everything before it should be torn down. With databases, the opposite is true.
AI has rewritten how a database is used. It has made the database's oldest guarantees more important than ever.
- Consistency changed meaning. It used to be about keeping replicas in step; now it has to hold across modalities — the records, text, vectors, and files that today live as four drifting copies in four systems. A context an agent trusts can't be eventually consistent with itself: once agents decide in production, one stale record isn't a metric, it's an incident.
- Scalability changes shape but not stakes: from making one database big to letting a million small ones coexist cheaply — scaling out when needed, to zero when idle.
- Reliability becomes a lifeline. An agent runs around the clock with no operator watching. The financial-grade high availability we spent fifteen years earning — once there to protect core transactions — becomes the lifeline of every single agent.
- Real-time is non-negotiable — and the bar just rose. The unit of work has gone from a single request to a full inference, and from simple reads and writes over structured rows to hybrid retrieval and multi-path recall over multimodal data — all of it now in the live path of a decision. An agent that can't assemble its context in real time can't support a live business. That is exactly why an agent's data foundation needs the reflexes of a production transactional database, not the lag of an offline analytical one.
What AI asks you to rewrite is the architecture; what it asks you never to compromise is the engineering floor. That tension — what changes, and what must not — is the whole question.
So what is an AI database?
Put the change and the constancy together, and a definition falls out — less an assertion than a consequence of everything above. An AI database has to be four things at once, and they come from two different places.
By workload demand.
- It has to be unified — multimodal data and online-and-offline computation on a single, strongly consistent, real-time foundation, so data is never split, never shuttled between systems, and the flywheel can turn.
- It has to be multimodal — structured data, vectors, text, and JSON processed and retrieved in one engine, because an agent's memory is cross-modal by nature.
By design principle —
- It has to be agent-friendly — memory, isolation, branching, rollback, and natural-language access as native capabilities, not a rack of external systems bolted togethe
- It has to be open — storage and compute decoupled, data in open formats on shared storage, and a free hand across infrastructure, clouds, and models, so the enterprise keeps three freedoms: where it runs, which models it uses, and ownership of its data.
Four things, none optional. And only one architecture satisfies all four at once — joining the openness, scale, and multimodality of the data lake with the transactions and real-time of the database, in a single system. The industry is starting to call that shape a lakebase — where the data lake and the database become one.
OceanBase's answer
Our answer is OceanBase AI Database. A database is strong on consistency, real-time, and reliability; a lake is strong on multimodal storage and open compute — and the AI era requires the two to become one. Relating multimodal data so it stays consistent, processing it in real time, and managing it as one is exactly the bottleneck that decides whether a model's, and an agent's, power can land inside an enterprise.
Making that merge work isn't a matter of gluing a lake and a database together. A lakebase has to grow outward from a kernel mature enough to be trusted with money — extending transactions and real-time to the lake, rather than bolting the hardest guarantees onto a lake or a vector engine after the fact. That is why we can build it: OceanBase has been heading toward this shape for years — from a distributed database in one engine, to transactions and analytics in one engine, and now to a lakebase.
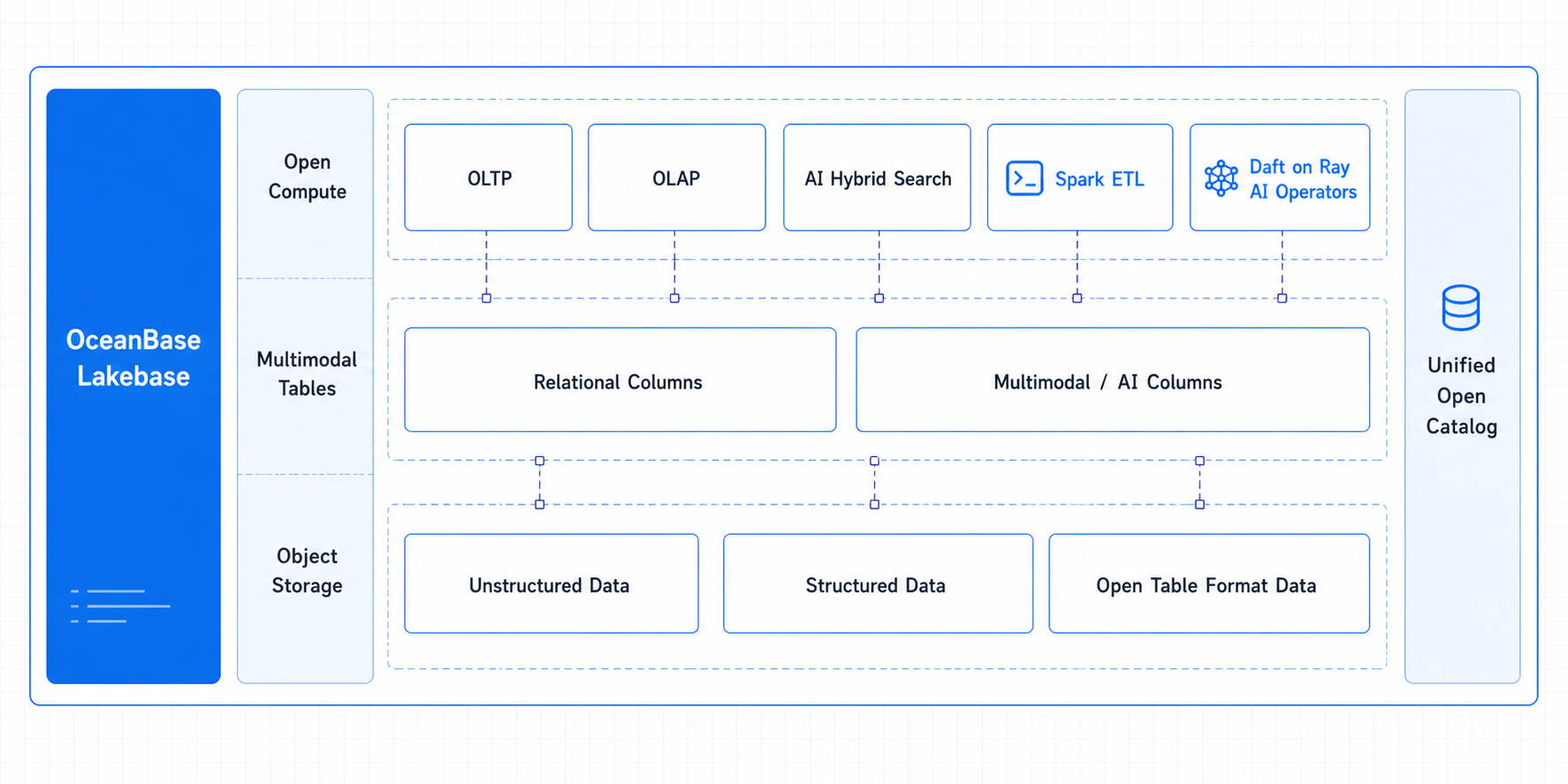
Here is what that core makes possible:
- One foundation, one copy of the data. The lake's open formats and scale and the database's transactions, consistency, and real-time in a single system — structured, semi-structured, and unstructured data under one catalog, with permissions and lineage holding across all of it.
- Multimodal tables. Text, images, audio, documents, JSON, and vectors enter the table itself, managed under one set of transactions, permissions, and lifecycle — and model outputs like embeddings, summaries, and labels persist alongside them as AI columns.
- Hybrid search in one query path. Scalar filters, full-text, and vector retrieval run together inside the database, with multi-path recall and ranking kept consistent with the source data — so an agent's context comes back accurate and fresh.
- Agent-friendly primitives. Long-term memory, context, and state are native; Fork Database spins up isolated sandboxes for safe trial and rollback; and millions of lightweight agents coexist at high density, waking on demand.
- An open design. Built on S3-compatible storage, Iceberg open tables, and a unified catalog, open to engines like Spark and Ray — so data isn't copied, converted, or locked in.
Building OceanBase for the AI Era
For the past fifteen years, OceanBase has been hardened in some of the most demanding production environments: systems where data cannot be wrong, service cannot stop, and recovery must happen fast enough that users do not feel the failure. Those requirements are not tied to one era of computing. They are the permanent floor for any system that businesses depend on.
And today, we are sharpening this lakebase capability inside Alibaba's and Ant's most demanding AI workloads. Just as how double 11 shopping festival once forced a distributed database into being, AI applications are now pushing the next generation of database architecture into shape. That is OceanBase's particular way of evolving — and over the next decade, our goal is a simple: to build OceanBase for the AI era.
If you're working on the data layer for AI, this is the problem we built OceanBase AI Database to solve. Explore OceanBase AI Database now!



Keep Reading
View all posts
The Future of Relational Databases
Yang Zhenkun, OceanBase founder and chief scientist, made a keynote speech at HICOOL Global Entrepreneurs Summit. Dr. Yang talked about the milestones of the world’s mainstream relational databases and shared his visions on the future of distributed databases. When Dr. E. F. Codd, an IBM researcher,...



What FinTech Infrastructure Demands in the AI Era
OceanBase has spent years working alongside leading fintech companies like AliPay, GCash, and DANA. Here's what we've learned about what fintech data infrastructure really needs, and how AI is raising the bar, and how OceanBase addresses the needs with an unified architecture.


OceanBase AI Database: Built on a Lakebase Architecture for the AI Era
OceanBase Lakebase unifies multi-modal data, transactions, analytics, and AI search in one engine for the agent era.
