Multi-AZ is not disaster recovery (and today proved it)

- Multi-AZ high availability is not the same as real disaster recovery, because a large regional or provider-level incident can still take all replicas down within the same blast radius.
- The practical recovery path is to make cross-region DR real first with tested runbooks and drill data, then add cross-cloud cold, warm, or primary/standby architectures based on actual RTO/RPO requirements.
- The biggest gap for most teams is not architecture on paper, but whether failover, restore, routing, and application reconnect have been rehearsed end to end under incident conditions.
A few hours ago, a datacenter in a major cloud region lost power to an entire availability zone. Not a server rack. Not a single building. The whole AZ went dark, and everything running on it went with it.
The provider’s status page was honest about the timeline: several hours.
For teams with production workloads in that zone, the next few hours looked like this: scrambling for runbooks that hadn’t been touched in months, discovering that the “cross-region standby” had never been drilled end-to-end, finding that the DNS cutover and connection string rotation and certificate refresh had been documented but never actually tested under incident conditions. What they thought was disaster recovery turned out to be something less: backups, and hope.
We’ve had versions of this conversation with customers across Asia-Pacific and North America many times. The pattern is consistent: teams believe they’re covered because they have HA configured. Then something large enough happens, and they find out the gap between “highly available” and “recoverable from an AZ outage” is bigger than they expected.
This post covers that gap — what it is, why standard multi-AZ HA doesn’t close it, and what architectures actually do.
Before you keep reading: a quick self-check
If any of these describes your situation, the rest of this post is relevant to you:
The problem with "we have multi-AZ"
Cloud databases have gotten genuinely good at node-level and AZ-level failures. Multi-AZ deployments, synchronous replication, automatic leader election — for a single bad host or a transient AZ blip, this works. Your database fails over in seconds. Nobody gets paged.
But a regional outage is a different failure mode, and multi-AZ HA doesn't help with it in the ways most teams assume. The reason is structural: your replicas across AZs are still running on the same provider's underlying infrastructure. Same control plane. Same network backbone in many cases. Same quota enforcement, same dependency services. A failure that's regional in scope — not just a building, but something in the provider's networking layer or compute scheduling — will affect all your AZs simultaneously. Three replicas, same blast radius.
We also see three specific gaps come up consistently when teams audit their DR posture honestly:
Cross-region and cross-cloud: don't confuse them
This distinction matters more than most teams realize, and the confusion leads to systematic underinvestment in the right places.
They also combine, and that's where mature architectures end up. A typical pattern: Cloud A / Region 1 as primary, Cloud A / Region 2 as cross-region DR, Cloud B / Region 1 as cross-cloud standby. That topology covers "my datacenter flooded" and "my vendor had a really bad day" simultaneously, without either leg making the other redundant. In Southeast Asia specifically, we often see teams pairing a regional cloud footprint with a second provider as their cross-cloud leg — not because one is better, but because provider diversification is its own form of risk management.
Start with cross-region. Add cross-cloud when the risk profile justifies it.
A decision path that works in practice
If you're making a platform decision (not just doing a one-off incident fix), this sequence tends to work well:
The most common failure pattern we see is skipping step 1, jumping straight to cross-cloud, and then discovering the cutover process is still manual and untested.
Four levels of HA — and which one you actually have
At OceanBase Cloud, we think about availability across four distinct failure layers, because the right architecture for each is different, and conflating them is how teams end up with gaps they don't know about.

Level 1 — Node failure
A server dies. OceanBase's distributed Multi-Paxos architecture handles this automatically: when a leader replica fails, the cluster elects a new one without human intervention. Connection interruption is measured in seconds. This is the solved problem — the baseline that every modern distributed database should provide.
Level 2 — Datacenter / AZ failure
An entire AZ goes down. Three replicas across physically separate locations with automatic failover. OceanBase also supports a 2F+1A topology: two full replicas and one lightweight arbiter node that participates in consensus without holding a full data copy. This cuts storage cost by roughly one-third compared to three full replicas, while preserving automatic failover. Worth knowing the option exists if cost is a constraint at scale.
Level 3 — Region failure
An entire geographic region goes dark. This is today's scenario. Full replicas syncing in real time to a second region; under appropriate deployment and network conditions, RPO approaches zero. Active-active across regions is supported for workloads that require it. This is the most direct response to what happened today, and for most teams it's where investment should be concentrated first.
Level 4 — Cloud provider failure
The provider itself has a vendor-level incident — not one region, but something affecting their infrastructure more broadly. Native cloud database services typically don't give you architectural tools to protect against the provider they run on. OceanBase Cloud's cross-cloud DR capability is the differentiating layer here. Three deployment modes cover different risk profiles.
The three cross-cloud DR modes — and the honest tradeoffs
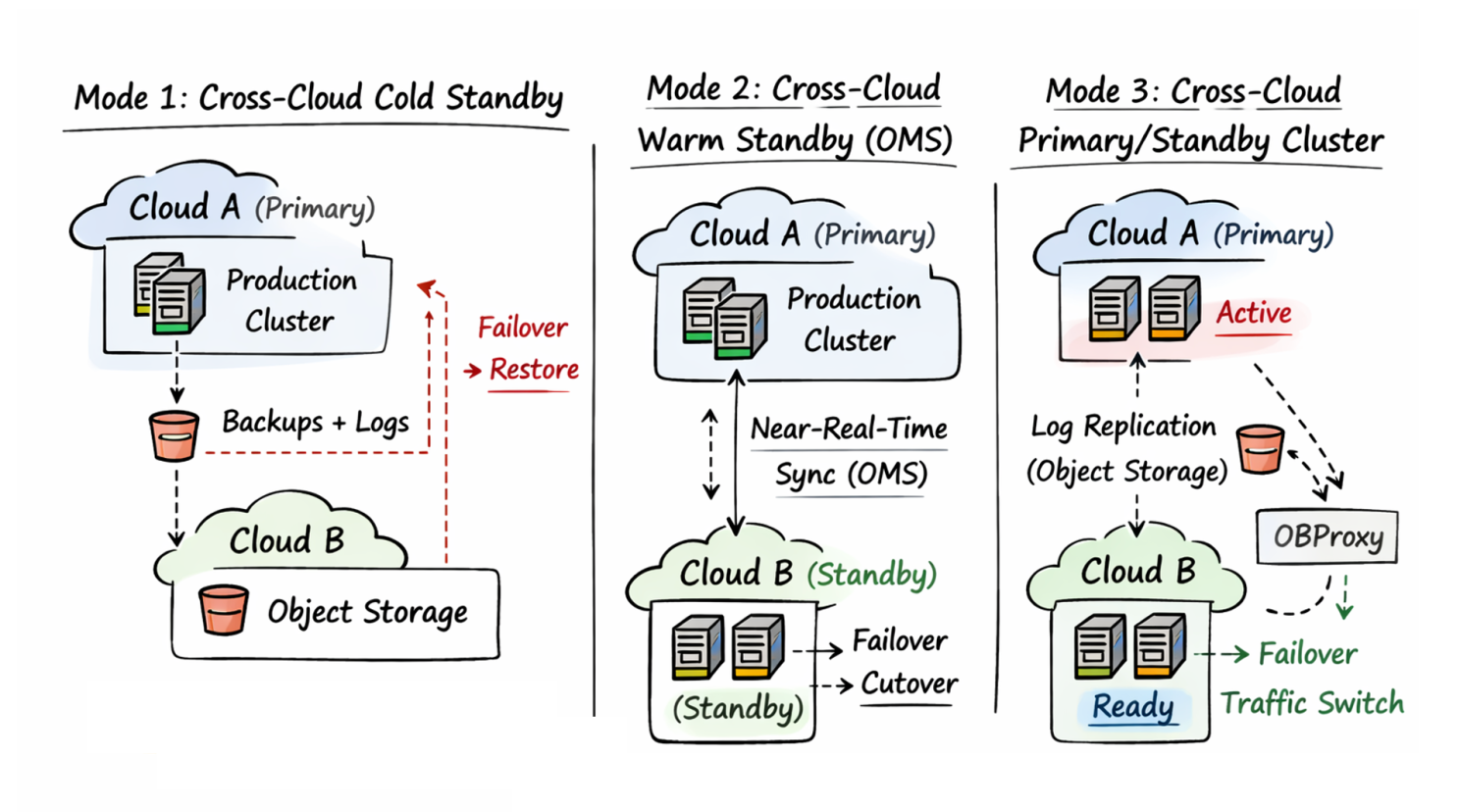
Mode 1: Cross-cloud cold standby
Right for: cost-sensitive workloads that can tolerate hour-scale RTO
Your primary cluster runs on Cloud A. Backups and log archives write continuously to Cloud B's object storage. If Cloud A fails, you restore from Cloud B.
The tradeoff is real and worth stating plainly: recovery time depends on data volume, network throughput, restore automation quality, and validation procedures. At a few hundred GB with well-tested automation, you might be back in under an hour. At multi-TB scale, you're looking at several hours minimum — teams often underestimate this because they test backup creation, not complete restore timing. Cold standby is the right starting point if cost is constrained; it eliminates "we lose everything" for a fraction of the cost of warm alternatives.
Cost drivers: object storage, cross-cloud egress during restore, and the people-time required to keep restores automated and periodically tested.
Mode 2: Cross-cloud warm standby via OMS
Right for: business-critical workloads targeting minute-scale RPO
OceanBase Migration Service (OMS) maintains a near-real-time sync link between Cloud A and Cloud B. When Cloud A has an incident, traffic cuts over to Cloud B — with far less data to replay and a recovery window that's predictable rather than open-ended.
The ongoing investment is operational discipline: a live sync link needs continuous replication lag monitoring, alerting when it falls behind, capacity headroom pre-provisioned on Cloud B, and regular consistency checks. None of that is technically hard, but it all requires ongoing attention. A warm standby that hasn't been maintained is often worse than cold standby, because teams assume it's ready when it isn't.
Cost drivers: always-on sync infrastructure (OMS), standby capacity, and ongoing operational overhead (monitoring, consistency checks, and incident drills).
Mode 3: Cross-cloud primary/standby cluster
Right for: mission-critical systems requiring the broadest fault-domain coverage
A full standby cluster on Cloud B stays in sync with the Cloud A primary via log archive replication over object storage — no dedicated leased line required, no VPC peering, no fixed bandwidth commitment. When Cloud A fails, traffic cuts over to Cloud B through a proxy layer (in OceanBase Cloud, OBProxy). Applications reconnect without changing connection strings; the proxy detects the new primary and reroutes automatically.
Acceptance criterion: a cutover should not require editing application configs or redeploying services. If it does, you don't have DR — you have a manual migration plan.
Three properties make this operationally viable at scale:
Cost drivers: a second cluster's steady-state resources, plus the discipline to drill cutovers and rollbacks on a fixed cadence.
The thing worth doing before the next incident
You don't need a staging environment or a change window to figure out where you actually stand. Run a tabletop exercise — one hour, the right people, three questions you have to answer with data rather than intuition:
The answers to those questions will tell you what your actual DR capability is, regardless of what the architecture diagram says.
Two additions that matter for leadership teams:
And two governance questions that prevent DR from turning into shelfware:
If the answers are unsatisfying, the lowest-cost first step is cross-region DR with a runbook you've actually run. Once that's solid, layer cross-cloud cold standby on top. Add warm standby or primary/standby cluster architecture where business requirements justify the investment. Build to the coverage your actual risk profile requires — not more, not less.
On cloud SLAs and where your responsibility starts
Cloud providers are essential partners — for OceanBase Cloud customers and for teams running on any major provider. The infrastructure, network, and managed service availability that cloud providers deliver, backed by SLA commitments, represents a level of reliability that would be practically impossible to replicate privately.
But an SLA defines availability of the service components the provider controls. It doesn't automatically guarantee continuity of your specific workload — your data integrity through a failover, your application's ability to reconnect, your capacity at a secondary site, the accuracy of a runbook written against infrastructure that's since changed.
Business continuity is an end-to-end engineering problem that runs from the provider's physical infrastructure through your database layer, your connection layer, your application, and your team's ability to execute a practiced procedure under real pressure. A cloud provider with nine 9s of infrastructure uptime can't protect you from an untested runbook.
What we've built at OceanBase Cloud is an attempt to make the database layer of that chain auditable: DR that can be productized, drilled, and verified. So that when the next status page banner goes up, your response is a rehearsed procedure — not the first time you've run it.
Questions about how cross-cloud HA would apply to your specific architecture? Reach out to the OceanBase team → — the engineers who designed these systems are the ones who respond.



Keep Reading
View all posts
OceanBase at VLDB 2024: Exploring the Future of Distributed Database
The 50th International Conference on Very Large Databases (VLDB 2024), one of the leading international conferences in the database field, took place in Guangzhou from August 26th to August 30th. Drawing leading scholars from the global database community, VLDB offered a concentrated display of the ...



The Future of Relational Databases
Yang Zhenkun, OceanBase founder and chief scientist, made a keynote speech at HICOOL Global Entrepreneurs Summit. Dr. Yang talked about the milestones of the world’s mainstream relational databases and shared his visions on the future of distributed databases. When Dr. E. F. Codd, an IBM researcher,...


What FinTech Infrastructure Demands in the AI Era
OceanBase has spent years working alongside leading fintech companies like AliPay, GCash, and DANA. Here's what we've learned about what fintech data infrastructure really needs, and how AI is raising the bar, and how OceanBase addresses the needs with an unified architecture.
